Full View
Scene Understanding
Object Recognition
Image / Face Retrieval
Facial Expression Analysis
Face Recognition
Image Set Classification
Dimensionality Reduction
Face Detection
|
>>You are here: Research
Scene Understanding (Aug. 2016 - Present)
Publication:

|
|
Env-QA: A Video Question Answering Benchmark
To equip AI system with the ability to understand dynamic ENVironments, we build a novel video Question Answering dataset named Env-QA. Env-QA contains 23K egocentric videos, where each video is composed of a series of events about exploring and interacting in the environment. It also provides 85K questions to evaluate the ability of understanding the composition, layout, and state changes of the environment presented by the events in the videos. Moreover, we propose a novel video QA model, Temporal Segmentation and Event Attention network (TSEA), which introduces event-level video representation and corresponding attention mechanisms to better extract environment information and answer questions.
-
Difei Gao, Ruiping Wang, Ziyi Bai, Xilin Chen, “Env-QA: A Video Question Answering Benchmark for Comprehensive Understanding of Dynamic Environments,” 18th IEEE International Conference on Computer Vision (ICCV 2021), pp. 1675-1685, Montreal, Canada, Oct. 11-17, 2021.
 [Supplemental Material] [code] [Supplemental Material] [code]
|
|
|
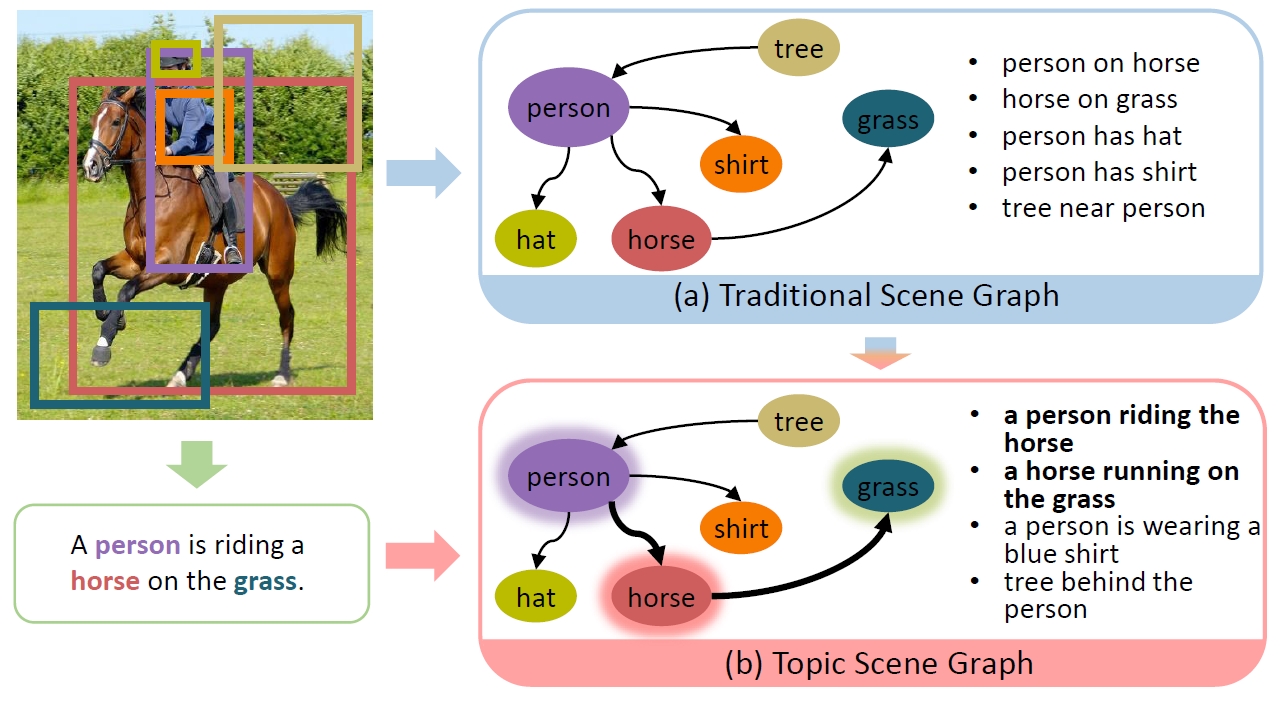
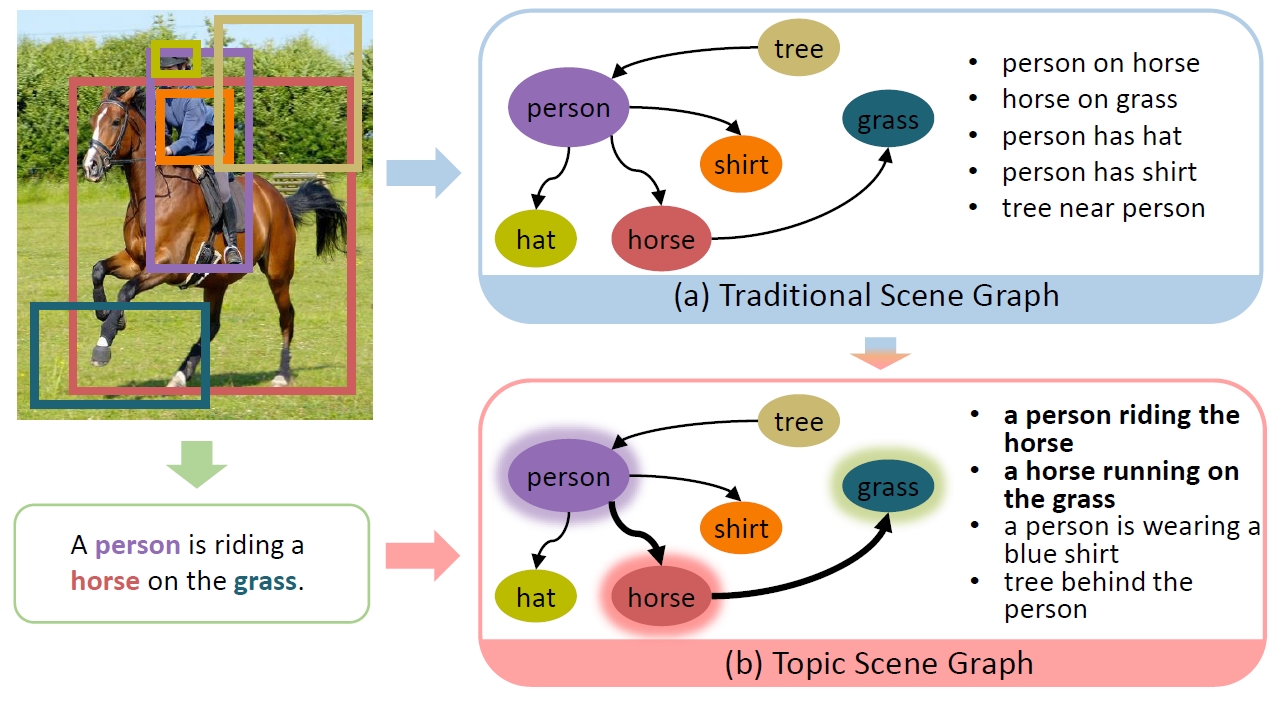
Topic Scene Graph (TSG)
If an image tells a story, the scene graph and image caption are the most popular narrators. Generally, a scene graph prefers to be an omniscient “generalist” while the image caption is more willing to be a “specialist” which outlines the gist. Lots of previous studies have found that a scene graph is not as practical as expected unless it can reduce the trivial contents and noises. In this respect, the image caption is a good teacher. To this end, we let the scene graph borrow the ability from the image caption so that it can be a specialist on the basis of remaining all-round, resulting in the so-called Topic Scene Graph. What an image caption pays attention to is distilled and passed to the scene graph for estimating the importance of partial events.
-
Wenbin Wang, Ruiping Wang, Xilin Chen, “Topic Scene Graph Generation by Attention Distillation from Caption,” 18th IEEE International Conference on Computer Vision (ICCV 2021), pp. 15900-15910, Montreal, Canada, Oct. 11-17, 2021. [Supplemental Material] [code]
|
|
|
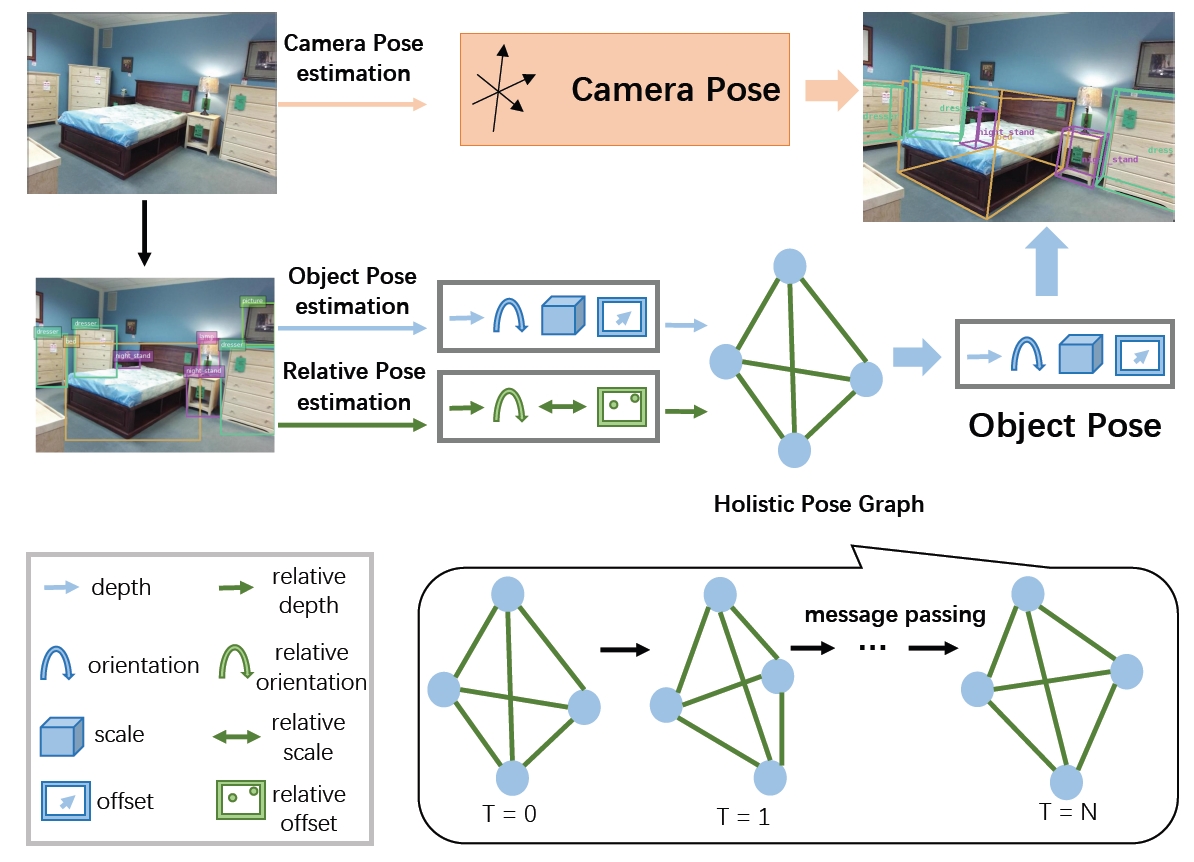
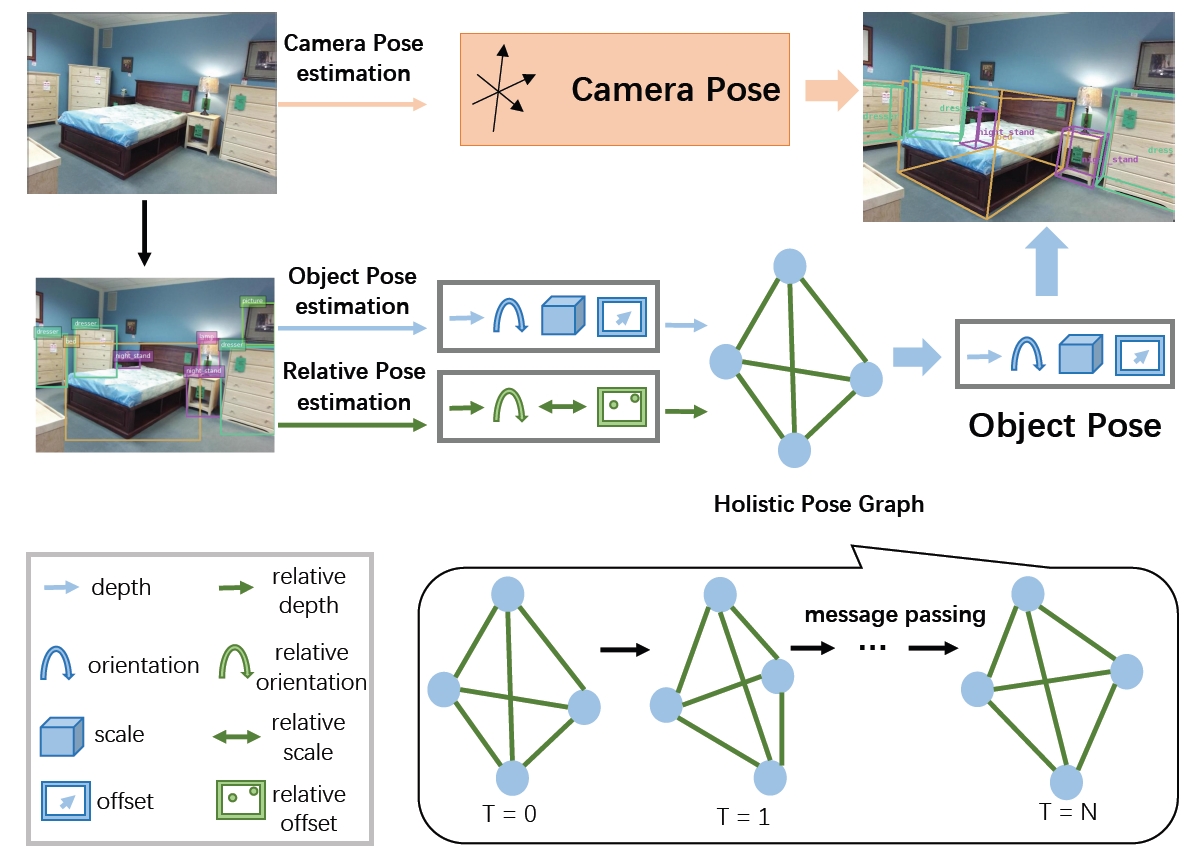
Holistic Pose Graph (HPG) for 3D Object Prediction
Due to the missing depth cues, it is essentially ambiguous to detect 3D objects from a single RGB image. We argue that modeling geometric structure among objects in a scene is very crucial, and thus elaborately devise the Holistic Pose Graph (HPG) that explicitly integrates all geometric poses including the object pose treated as nodes and the relative pose treated as edges. The inference of the HPG uses GRU to encode the pose features from their corresponding regions in a single RGB image, and passes messages along the graph structure iteratively to improve the predicted poses. To further enhance the correspondence between the object pose and the relative pose, we propose a novel consistency loss to explicitly measure the deviations between them. Finally, we apply Holistic Pose Estimation (HPE) to jointly evaluate the predictions of both the independent object pose and the relative pose.
-
Jiwei Xiao, Ruiping Wang, Xilin Chen, “Holistic Pose Graph: Modeling Geometric Structure among Objects in a Scene using Graph Inference for 3D Object Prediction,” 18th IEEE International Conference on Computer Vision (ICCV 2021), pp. 12717–12726, Montreal, Canada, Oct. 11-17, 2021. (Oral) [Supplemental Material] [code]
|
|
|
FAIEr: Fidelity and Adequacy Ensured Image Caption Evaluation
When humans evaluate a caption, they usually consider multiple aspects, such as whether it is related to the target image without distortion, how much image gist it conveys, as well as how fluent and beautiful the language and wording is. The above three different evaluation orientations can be summarized as fidelity, adequacy, and fluency. Inspired by human judges, we propose a learning-based metric named FAIEr to ensure evaluating the fidelity and adequacy of the captions. Since image captioning involves two different modalities, we employ the scene graph as a bridge between them to represent both images and captions. FAIEr mainly regards the visual scene graph as the criterion to measure the fidelity. Then for evaluating the adequacy of the candidate caption, it highlights the image gist on the visual scene graph under the guidance of the reference captions.
-
Sijin Wang, Ziwei Yao, Ruiping Wang, Zhongqin Wu, Xilin Chen, “FAIEr: Fidelity and Adequacy Ensured Image Caption Evaluation,” IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2021), pp. 14050–14059, June 19-25, 2021. [Supplemental Material] [code]
|
|
|
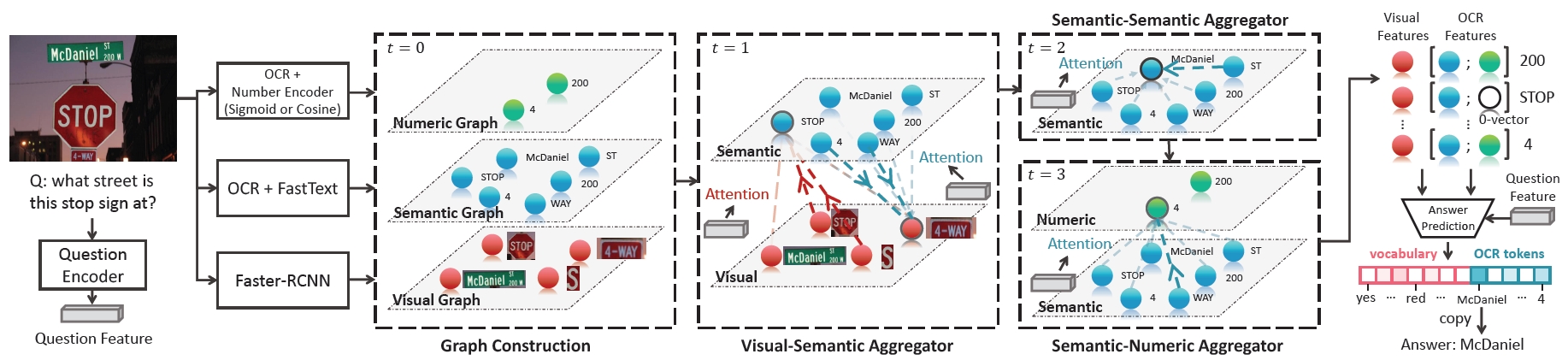
Multi-Modal Graph Neural Network (MM-GNN) for VQA
Answering questions that require reading texts in an image is challenging for current models. One key difficulty of this task is that rare, polysemous, and ambiguous words frequently appear in images, e.g. names of places, products, and sports teams. We propose a novel VQA approach, Multi-Modal Graph Neural Network (MM-GNN). It first represents an image as a graph consisting of three sub-graphs, depicting visual, semantic, and numeric modalities respectively. Then, we introduce three aggregators which guide the message passing from one graph to another to utilize the contexts in various modalities, so as to refine the features of nodes. The updated nodes have better features for the downstream question answering module.
-
Difei Gao, Ke Li, Ruiping Wang, Shiguang Shan, Xilin Chen, “Multi-Modal Graph Neural Network for Joint Reasoning on Vision and Scene Text,” IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2020), pp. 12746–12756, Seattle, WA, June 14-19, 2020. [Supplemental Material] [code]
|
|
|
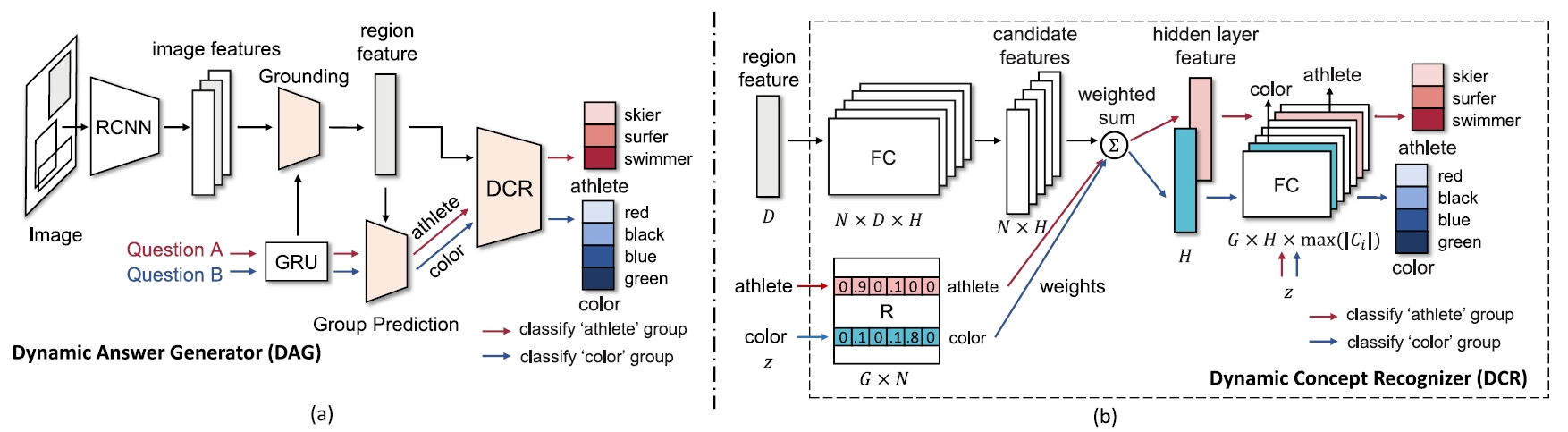
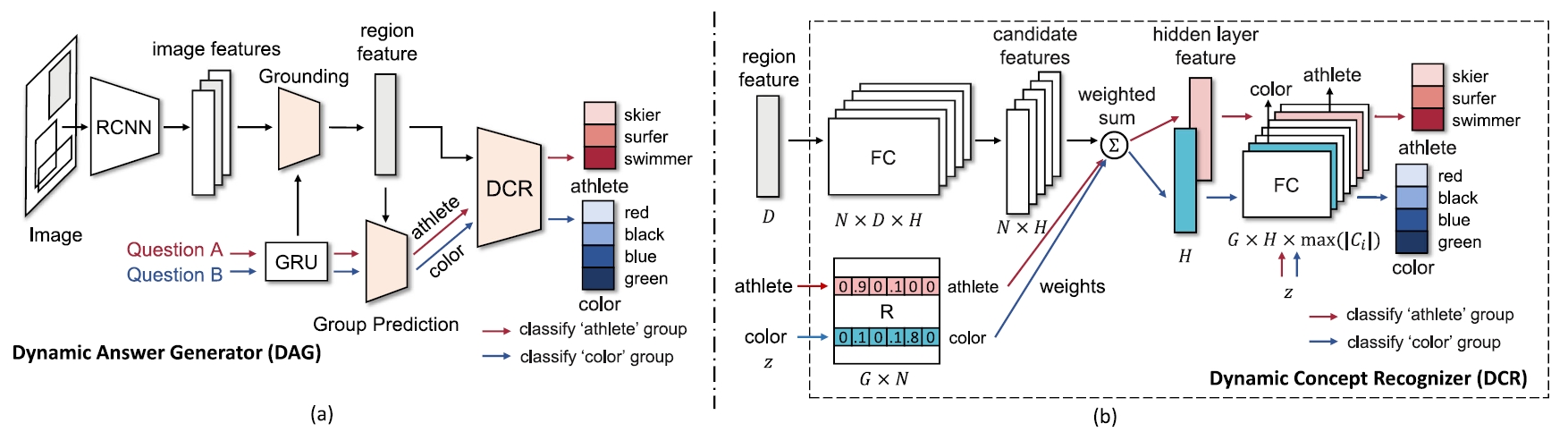
Dynamic Concept Recognizer (DCR) for VQA
We propose a novel visual recognition module named Dynamic Concept Recognizer (DCR), which is easy to be plugged in an attention-based VQA model, to utilize the semantics of the labels in answer prediction. Concretely, we introduce two key features in DCR: 1) a novel structural label space to depict the difference of semantics between concepts, where the labels in new label space are assigned to different groups according to their meanings. 2) A feature attention mechanism to capture the similarity between relevant groups of concepts. This type of semantic information helps sub-recognizers for relevant groups to adaptively share part of modules and to share the knowledge between relevant sub-recognizers to facilitate the learning procedure.
-
Difei Gao, Ruiping Wang, Shiguang Shan, Xilin Chen, “Learning to Recognize Visual Concepts for Visual Question Answering with Structural Label Space,” IEEE Journal of Selected Topics in Signal Processing, vol. 14, no. 3, pp. 494-505, Mar. 2020.
|
|
|
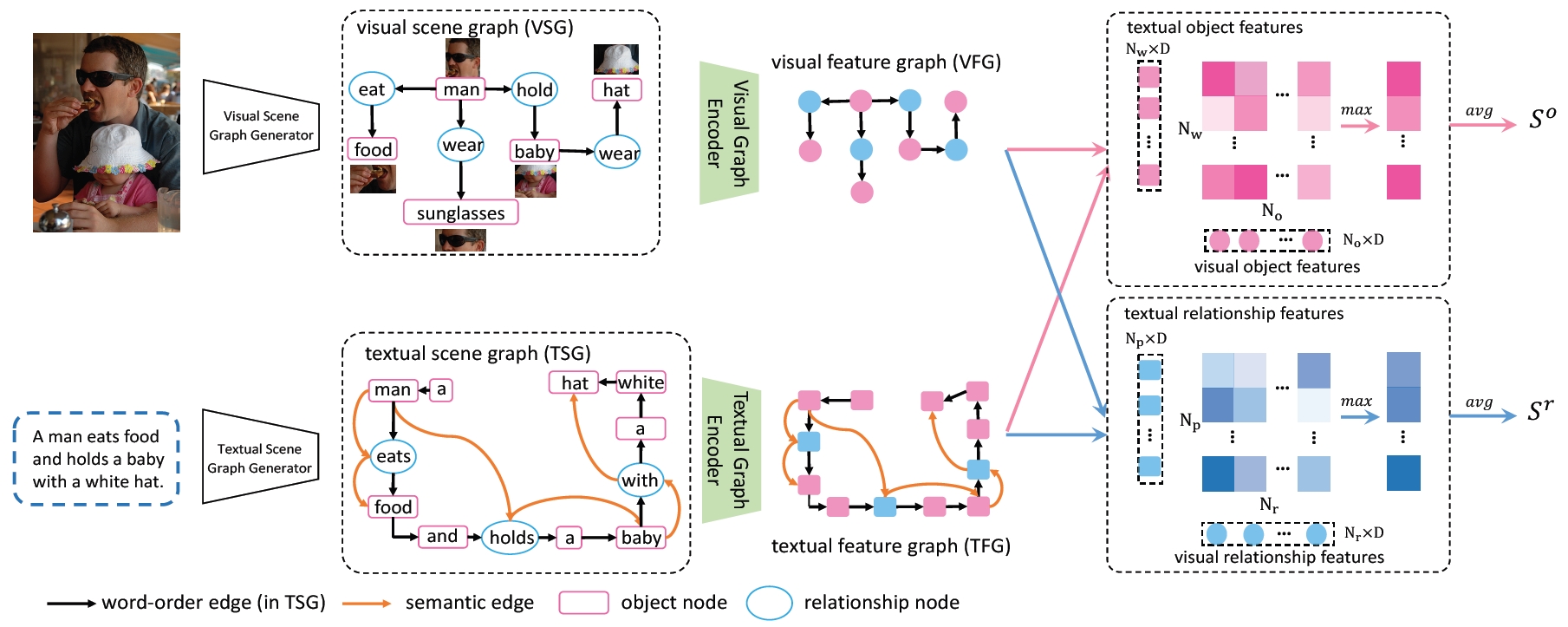
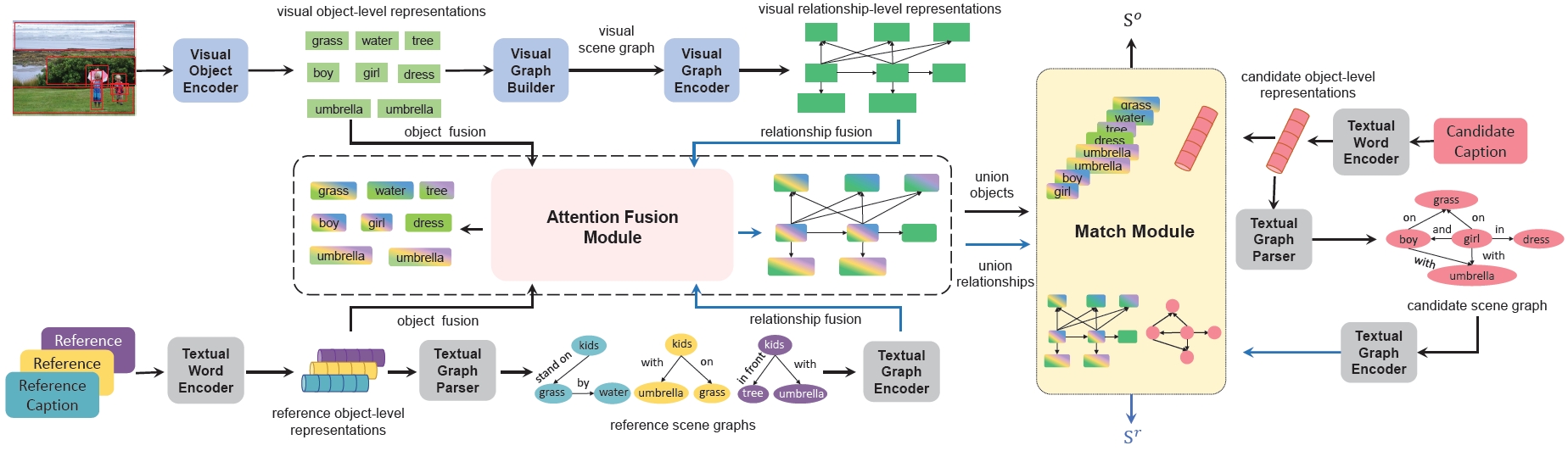
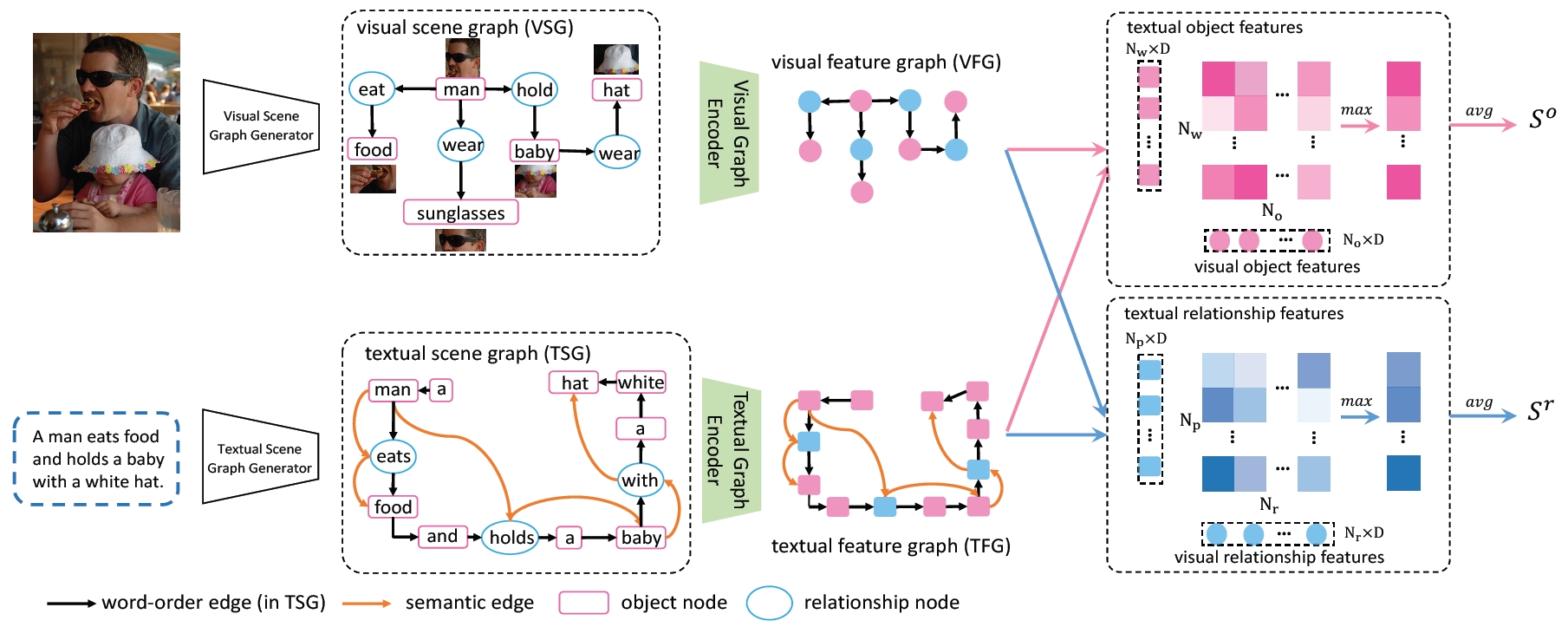
Scene Graph Matching (SGM) for Image-Text Retrieval
We propose to represent image and text with two kinds of scene graphs: visual scene graph (VSG) and textual scene graph (TSG), each of which is exploited to jointly characterize objects and relationships in the corresponding modality. The image-text retrieval task is then naturally formulated as cross-modal scene graph matching. Specifically, we design two particular scene graph encoders in our model for VSG and TSG, which can refine the representation of each node on the graph by aggregating neighborhood information. As a result, both object-level and relationship-level cross-modal features can be obtained, which favorably enables us to evaluate the similarity of image and text in the two levels in a more plausible way.
-
Sijin Wang, Ruiping Wang, Ziwei Yao, Shiguang Shan, Xilin Chen, “Cross-modal Scene Graph Matching for Relationship-aware Image-Text Retrieval,” IEEE Winter Conference of Applications on Computer Vision (WACV 2020), pp. 1508–1517, Aspen, CO, Mar. 2-5, 2020. [Supplemental Material] [code]
|

|
|
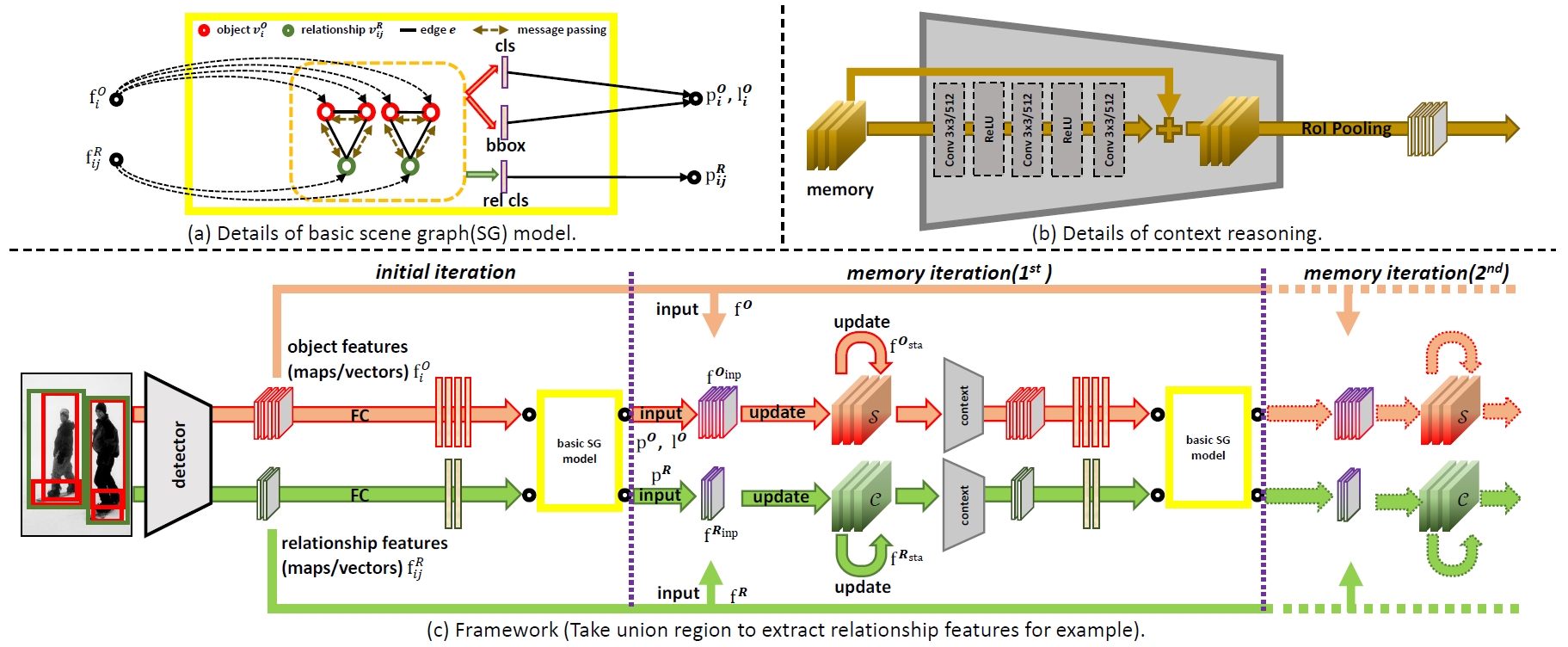
Hierarchical Entity Tree (HET) for Scene Graph Generation
We argue that a desirable scene graph should be hierarchically constructed, and introduce a new scheme for modeling scene graph. A scene is represented by a human-mimetic Hierarchical Entity Tree (HET) consisting of a series of image regions. To generate a scene graph based on HET, we parse HET with a Hybrid Long Short-Term Memory (Hybrid-LSTM) which specifically encodes hierarchy and siblings context to capture the structured information embedded in HET. To further prioritize key relations in the scene graph, we devise a Relation Ranking Module (RRM) to dynamically adjust their rankings by learning to capture humans' subjective perceptive habits from objective entity saliency and size.
-
Wenbin Wang, Ruiping Wang, Shiguang Shan, Xilin Chen, “Sketching Image Gist: Human-Mimetic Hierarchical Scene Graph Generation,” 16th European Conference on Computer Vision (ECCV 2020), LNCS 12358, pp. 222–239, Aug. 23-28, 2020. [Supplemental Material] [code]
|
|
|
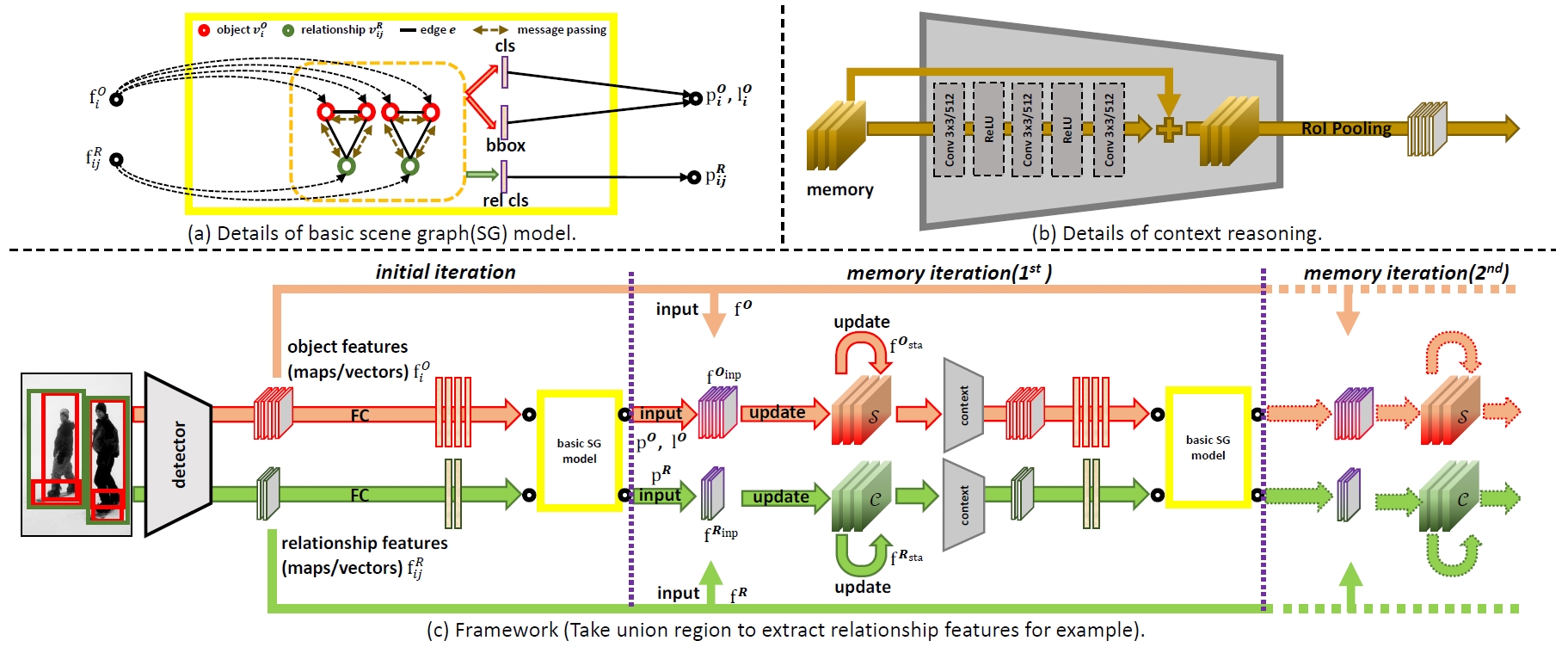
Memory Network (MemNet) for Scene Graph Generation
Relationship is the core of scene graph, but its prediction is far from satisfying because of its complex visual diversity. Our observation on current datasets reveals that there exists intimate association among relationships. We especially construct context for relationships where all of them are gathered so that the recognition could benefit from their association. In order to discover effective pattern for relationship, traditional relationship feature extraction methods such as using union region or combination of subject-object feature pairs are replaced with our proposed intersection region which focuses on more essential parts.
-
Wenbin Wang, Ruiping Wang, Shiguang Shan, Xilin Chen, “Exploring Context and Visual Pattern of Relationship for Scene Graph Generation,” IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2019), pp. 8180-8189, Long Beach, CA, June 16-20, 2019. [Supplemental Material] [code]
|
|
|
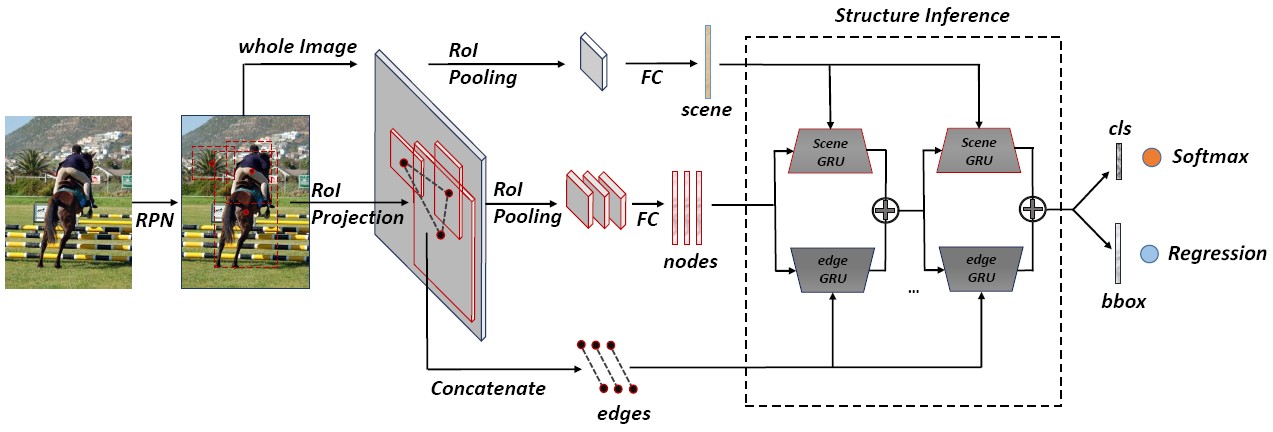
Structure Inference Network (SIN) for Object Detection
We propose an object detection algorithm that not only considers object visual appearance, but also makes use of two kinds of context including scene contextual information and object relationships within a single image. Therefore, object detection is regarded as both a cognition problem and a reasoning problem when leveraging these structured information. Specifically, this paper formulates object detection as a problem of graph structure inference, where given an image the objects are treated as nodes in a graph and relationships between the objects are modeled as edges in such graph. To this end, we present a so-called Structure Inference Network (SIN), a detector that incorporates into a typical detection framework (e.g. Faster R-CNN) with a graphical model which aims to infer object state.
-
Yong Liu, Ruiping Wang, Shiguang Shan, Xilin Chen, “Structure Inference Net: Object Detection Using Scene-Level Context and Instance-Level Relationships,” IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2018), pp. 6985-6994, Salt Lake City, UT, June 18-22, 2018. [Supplemental Material] [code]
|
|
|
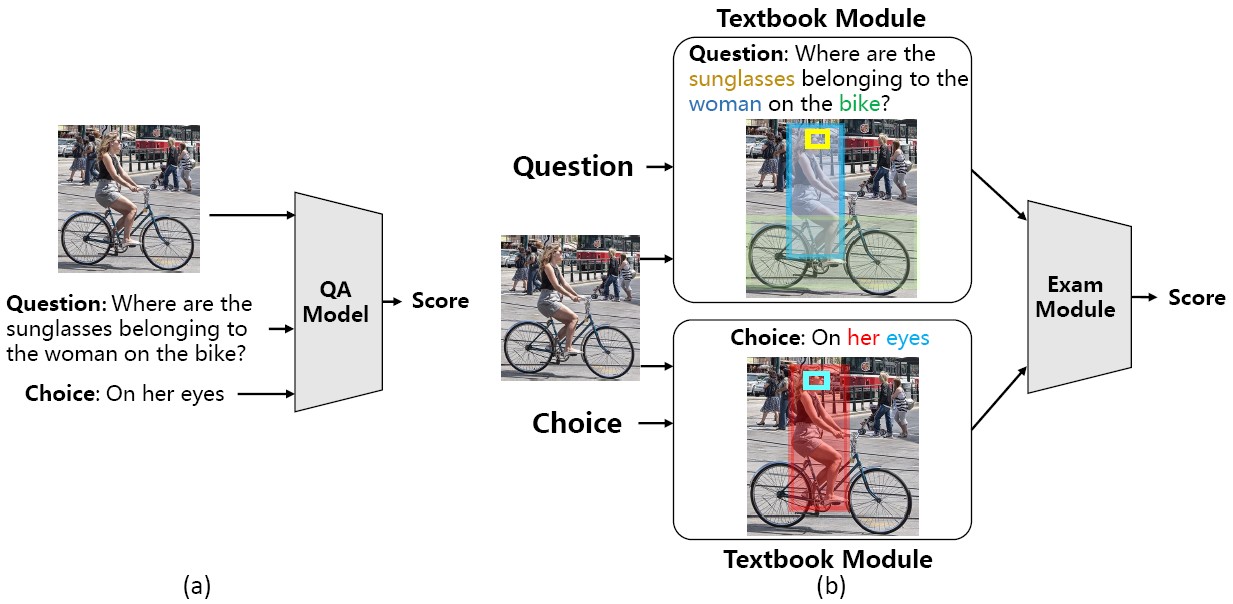
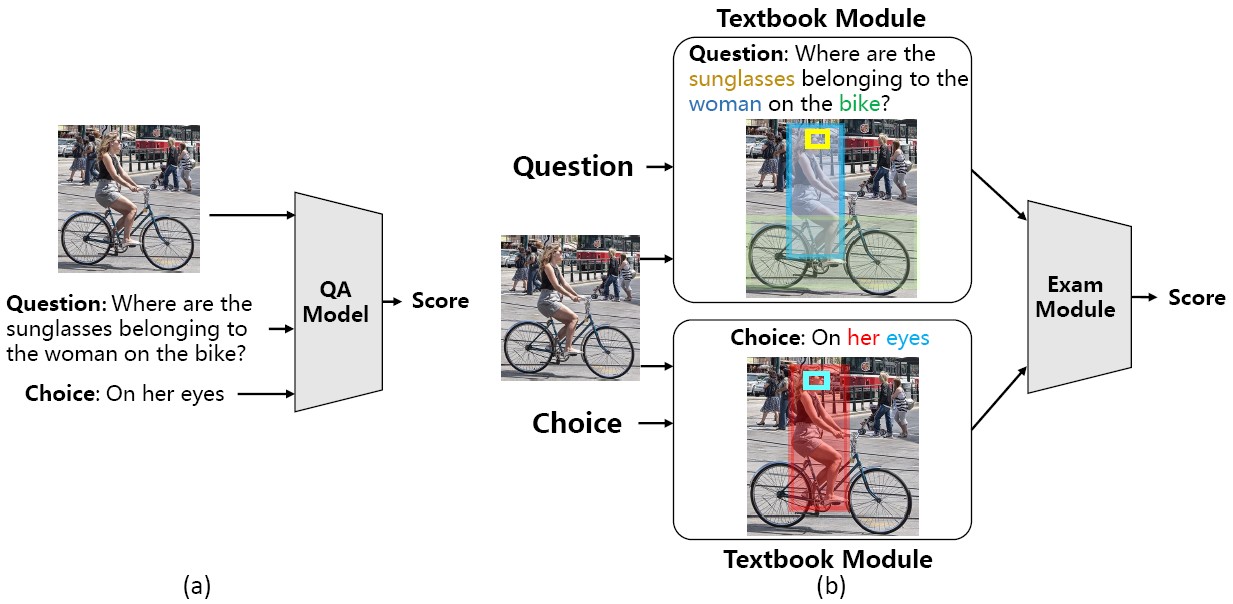
Visual Textbook Network (VTN) for VQA
Recent deep neural networks have achieved promising results on Visual Question Answering (VQA) tasks. However, many works have shown that a high accuracy does not always guarantee that the VQA system correctly understands the contents of images and questions, which are what we really care about. Attention based models can locate the regions related to answers, and may demonstrate a promising understanding of image and question. However, the key components of generating correct location, i.e. visual semantic alignments and semantic reasoning, are still obscure and invisible. To deal with this problem, we introduce a two-stage model Visual Textbook Network (VTN), which is made up by two modules to produce more reasonable answers.
-
Difei Gao, Ruiping Wang, Shiguang Shan, Xilin Chen, “Visual Textbook Network: Watch Carefully before Answering Visual Questions,” 28th British Machine Vision Conference (BMVC 2017), London, UK, Sep. 4-7, 2017.
|
Object Recognition (Mar. 2015 - Present)
Publication:
|
|
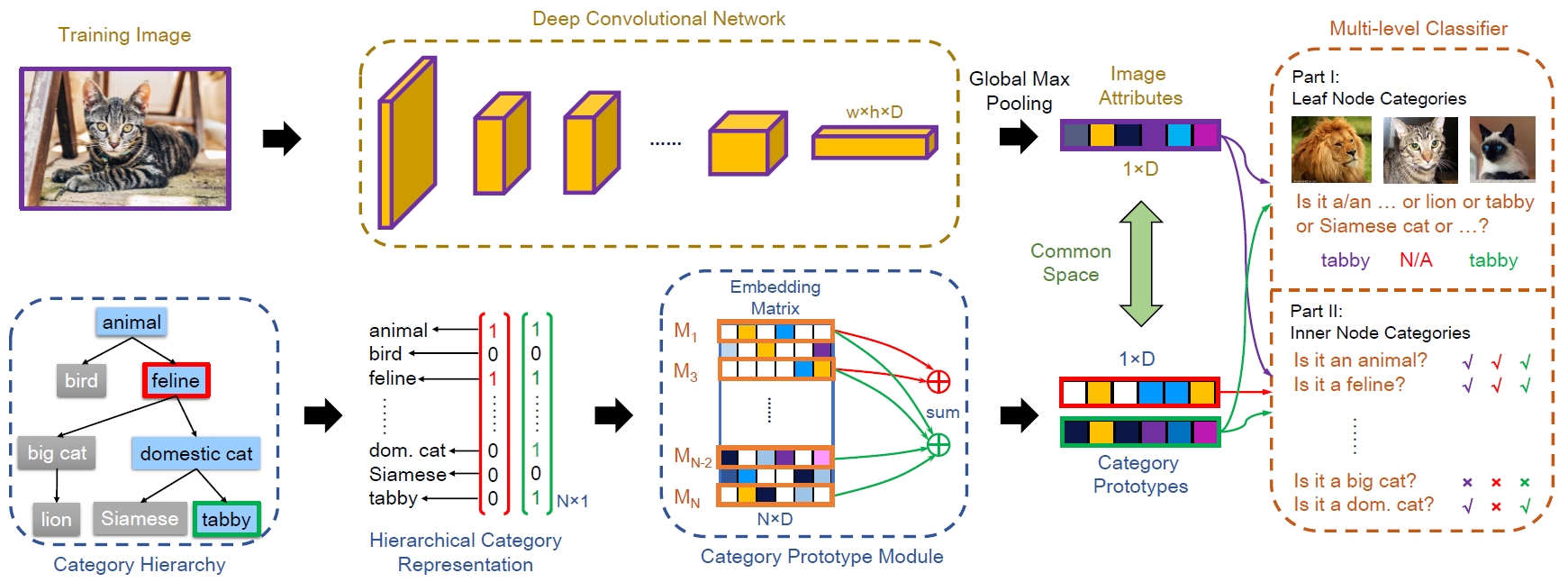
Hierarchical Criteria Network (HCN)
State-of-the-art classification models are usually considered as black boxes since their decision processes are implicit to humans. On the contrary, human experts classify objects according to a set of explicit hierarchical criteria. For example, "tabby is a domestic cat with stripes, dots, or lines", where tabby is defined by combining its superordinate category (domestic cat) and some certain attributes (e.g. has stripes). Inspired by this mechanism, we propose an interpretable Hierarchical Criteria Network (HCN) by additionally learning such criteria. To achieve this goal, images and semantic entities (e.g. taxonomies and attributes) are embedded into a common space, where each category can be represented by the linear combination of its superordinate category and a set of learned discriminative attributes. Specifically, a two-stream convolutional neural network (CNN) is elaborately devised, which embeds images and taxonomies with the two streams respectively. The model is trained by minimizing the prediction error of hierarchy labels on both streams.
-
Haomiao Liu, Ruiping Wang, Shiguang Shan, Xilin Chen, “What is a Tabby? Interpretable Model Decisions by Learning Attribute-Based Classification Criteria,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 43, no. 5, pp. 1791–1807, May 2021. [code]
|
|
|
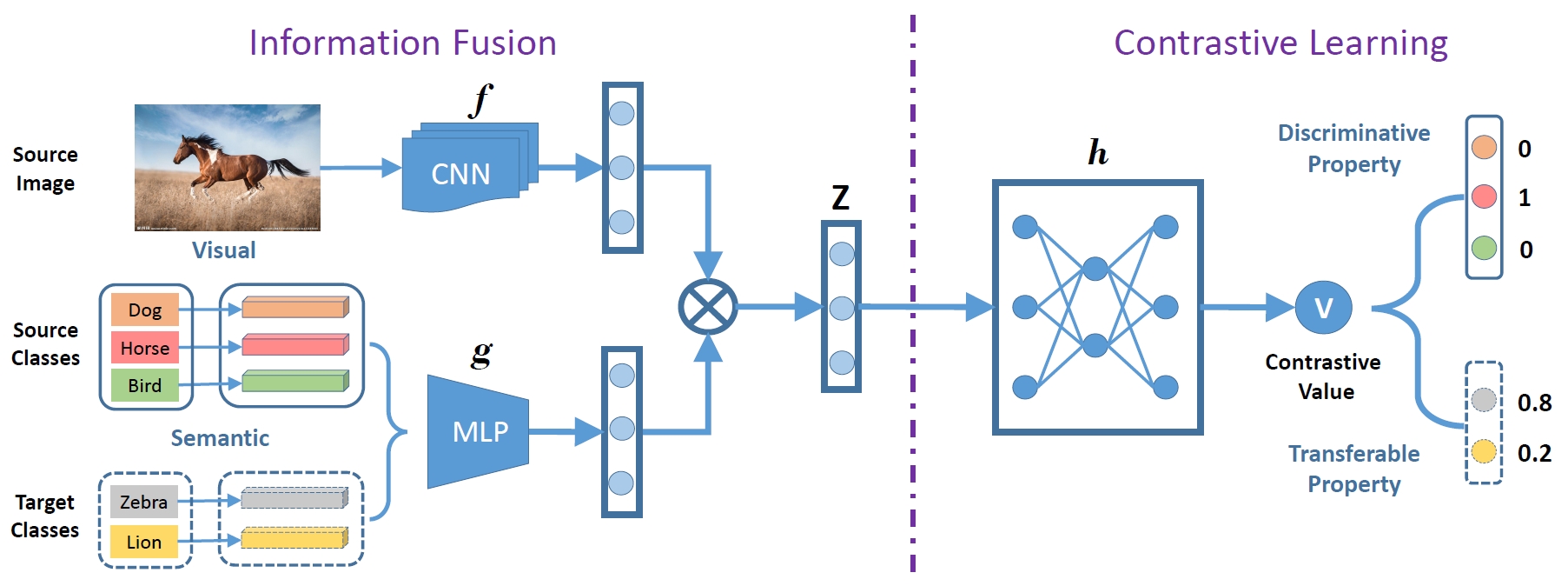
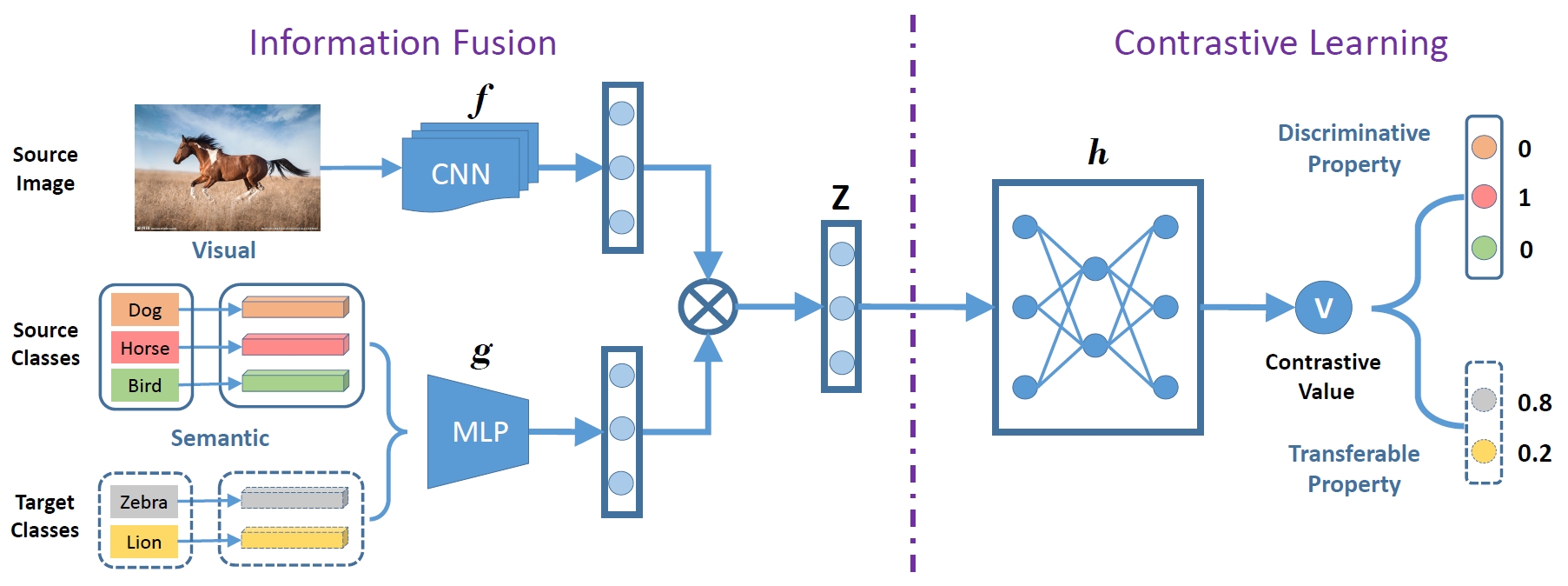
Transferable Contrastive Network (TCN)
Although ZSL has made great progress in recent years, most existing approaches are easy to overfit the sources classes in generalized zero-shot learning (GZSL) task, which indicates that they learn little knowledge about target classes. To tackle such problem, we propose a novel Transferable Contrastive Network (TCN) that explicitly transfers knowledge from the source classes to the target classes. It automatically contrasts one image with different classes to judge whether they are consistent or not. By exploiting the class similarities to make knowledge transfer from source images to similar target classes, our approach is more robust to recognize the target images.
-
Huajie Jiang, Ruiping Wang, Shiguang Shan, Xilin Chen, “Transferable Contrastive Network for Generalized Zero-Shot Learning,” 17th IEEE International Conference on Computer Vision (ICCV 2019), pp. 9764-9773, Seoul, Korea, Oct. 27-Nov. 2, 2019. [code]
|
|
|
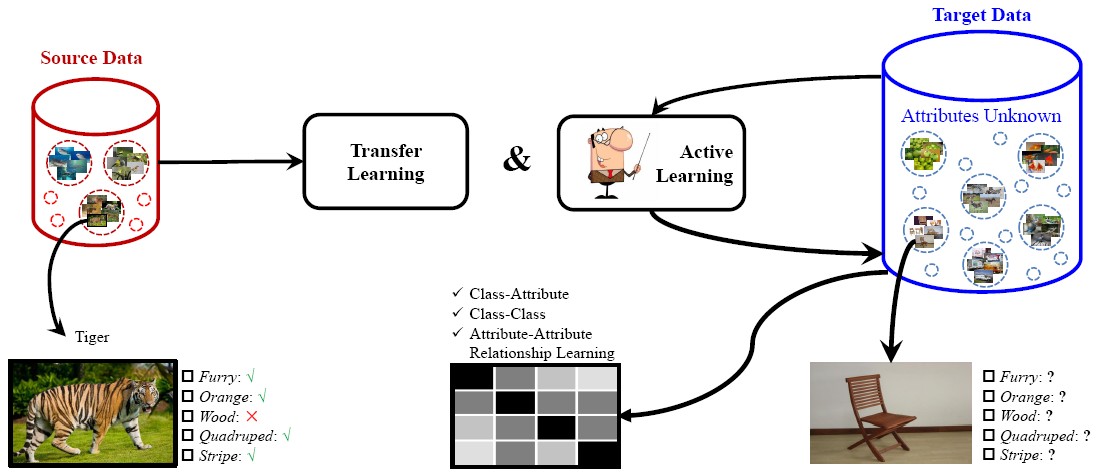
Attribute Annotation by Active Knowledge Transfer
We propose a novel framework to perform effective attribute annotations. Based on the common knowledge that attributes can be shared among different classes, we leverage the benefits of transfer learning and active learning together to transfer knowledge from some existing small attribute databases to large-scale target databases. In order to learn more robust attribute models, attribute relationships are incorporated to assist the learning process. Using the proposed framework, we conduct extensive experiments on two large-scale image databases, i.e. ImageNet and SUN Attribute, where high-quality automatic attribute annotations are obtained.
-
Huajie Jiang, Ruiping Wang, Shiguang Shan, Yan Li, Haomiao Liu, Xilin Chen, “Attribute Annotation on Large Scale Image Database by Active Knowledge Transfer,” Image and Vision Computing, vol. 78, pp. 1-13, Oct. 2018.
|
|
|
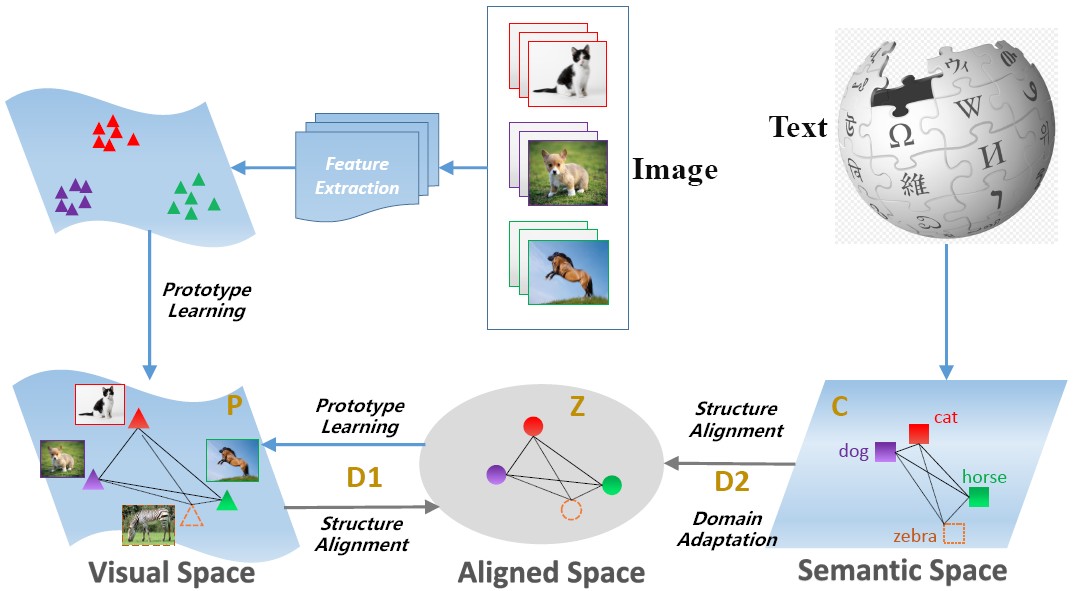
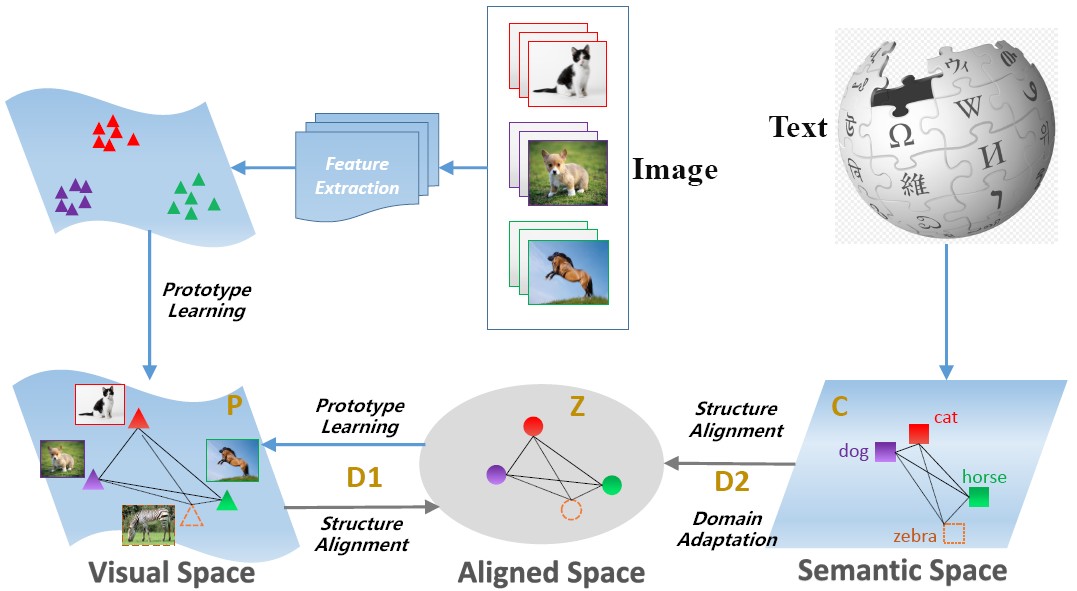
Coupled Dictionary Learning (CDL)
Recently most ZSL approaches focus on learning visual-semantic embeddings to transfer knowledge from the auxiliary datasets to the novel classes. However, few works study whether the semantic information is discriminative or not for the recognition task. To tackle such problem, we propose a coupled dictionary learning approach to align the visual-semantic structures, where the discriminative information lying in the visual space is utilized to improve the less discriminative semantic space. Then the prototypes of novel classes are formed by sharing the aligned visual-semantic structures. In this way, zero-shot recognition can be performed directly by nearest neighbour approach.
-
Huajie Jiang, Ruiping Wang, Shiguang Shan, Xilin Chen, “Learning Class Prototypes via Structure Alignment for Zero-Shot Recognition,” 15th European Conference on Computer Vision (ECCV 2018), LNCS 11214, pp. 121–138, Munich, Germany, Sep. 8-14, 2018. [Supplemental Material] [code]
|
|
|
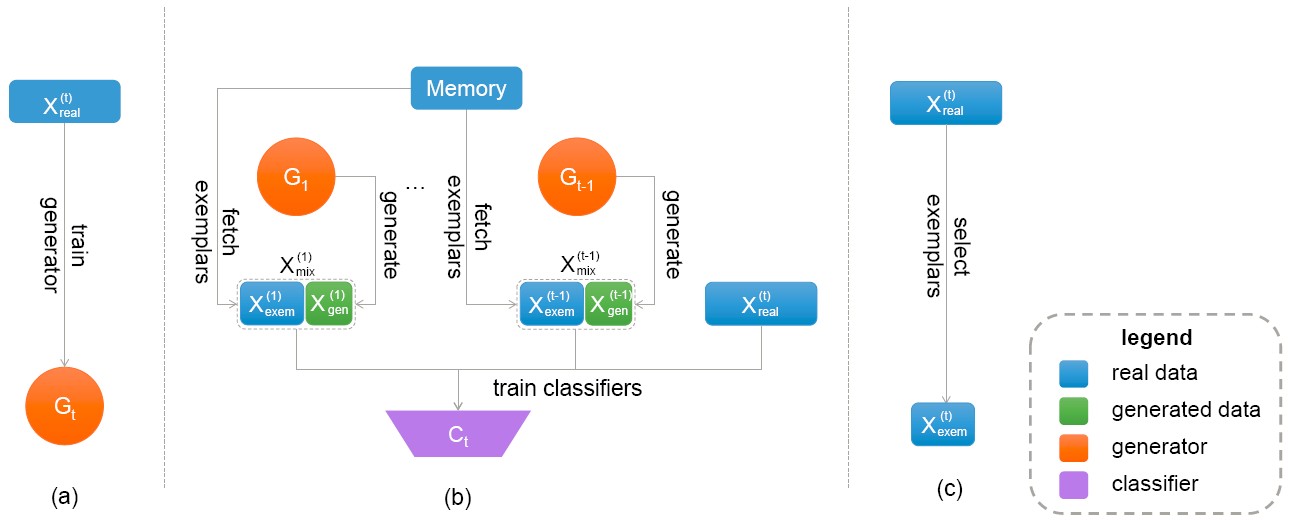
Exemplar-Supported Generative Reproduction (ESGR)
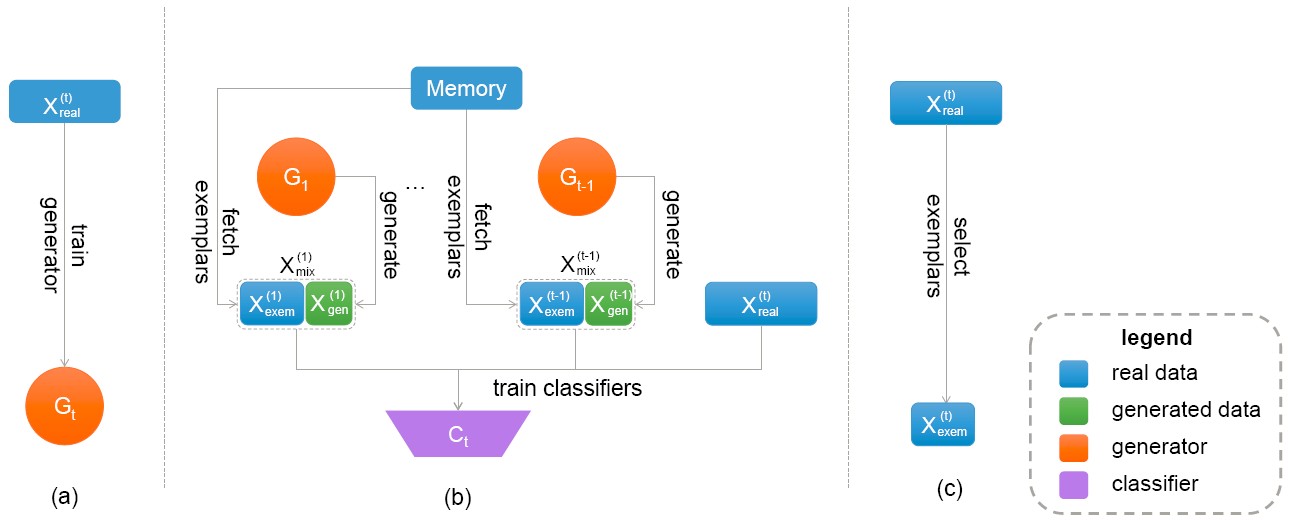
Incremental learning with deep neural networks often suffers from catastrophic forgetting, where newly learned patterns may completely erase the previous knowledge. We propose a novel class incremental learning method called Exemplar-Supported Generative Reproduction (ESGR) that can better reconstruct memory of old classes and mitigate catastrophic forgetting. Specifically, we use Generative Adversarial Networks (GANs) to model the underlying distributions of old classes and select additional real exemplars as anchors to support the learned distribution. When learning from new class samples, synthesized data generated by GANs and real exemplars stored in the memory for old classes can be jointly reviewed to mitigate catastrophic forgetting.
-
Chen He, Ruiping Wang, Shiguang Shan, Xilin Chen, “Exemplar-Supported Generative Reproduction for Class Incremental Learning,” 29th British Machine Vision Conference (BMVC 2018), Newcastle upon Tyne, UK, Sep. 3-6, 2018. [Supplemental Material] [code]
|
|
|
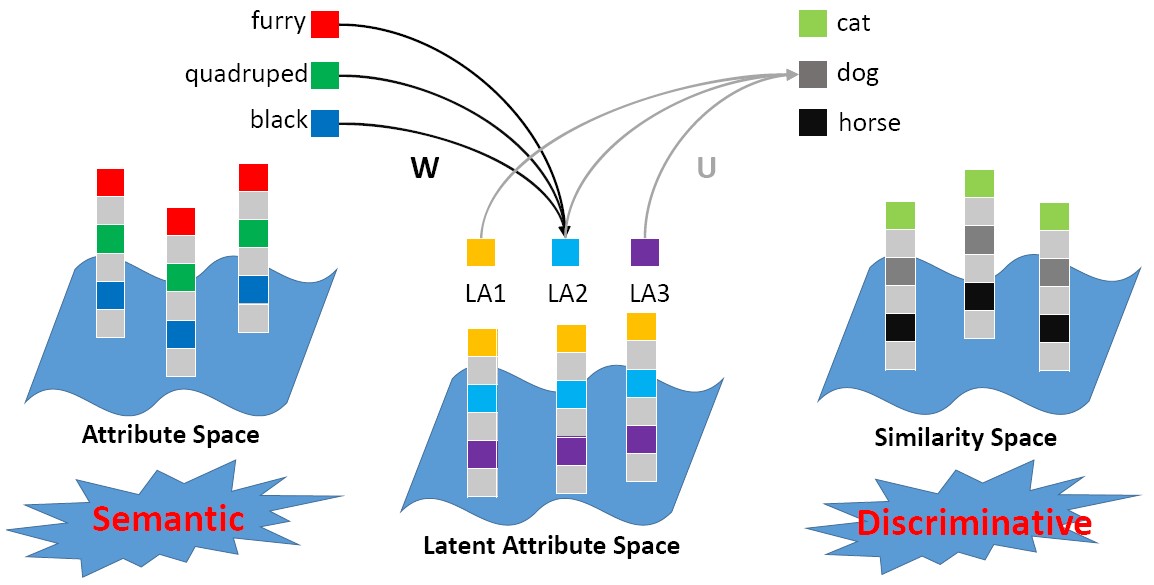
Latent Attribute Dictionary (LAD)
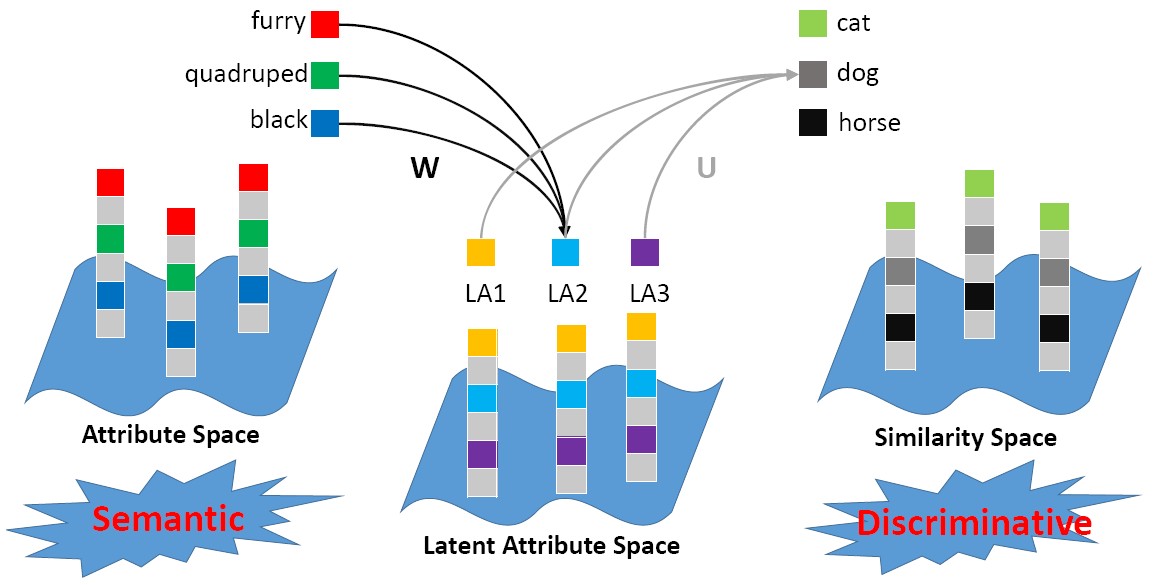
Zero-shot learning (ZSL) aims to transfer knowledge from observed classes to the unseen classes, based on the assumption that both the seen and unseen classes share a common semantic space, among which attributes enjoy a great popularity. We propose to learn a latent attribute space, which is not only discriminative but also semantic-preserving, to perform the ZSL task. A dictionary learning framework is exploited to connect the latent attribute space with attribute space and similarity space.
-
Huajie Jiang, Ruiping Wang, Shiguang Shan, Yi Yang, Xilin Chen, “Learning Discriminative Latent Attributes for Zero-Shot Classification,” 16th IEEE International Conference on Computer Vision (ICCV 2017), pp. 4223-4232, Venice, Italy, Oct. 22-29, 2017. [Supplemental Material] [code]
|
Image / Face Retrieval (Sep. 2013 - Present)
Publication:
|
|
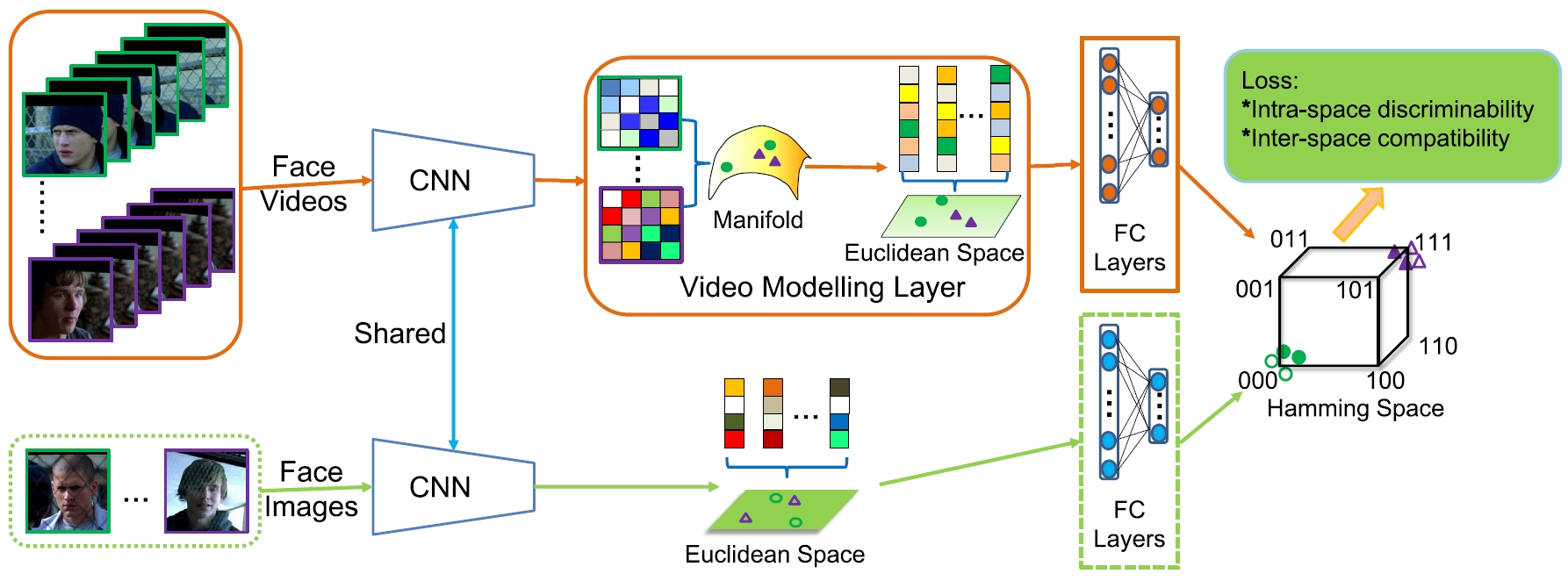
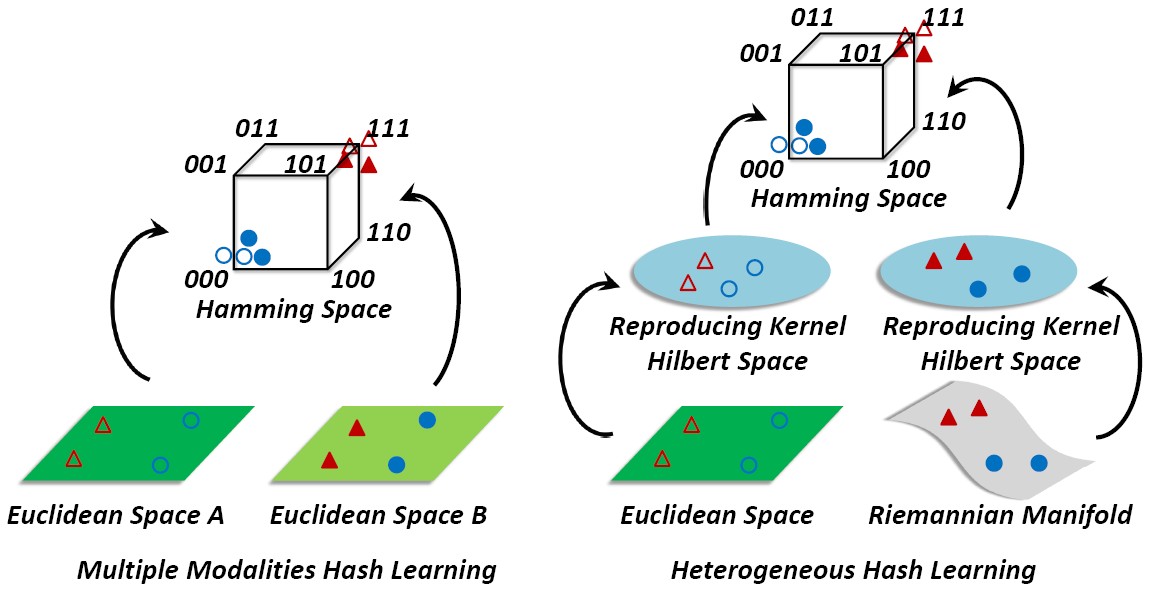
Deep Heterogeneous Hashing (DHH)
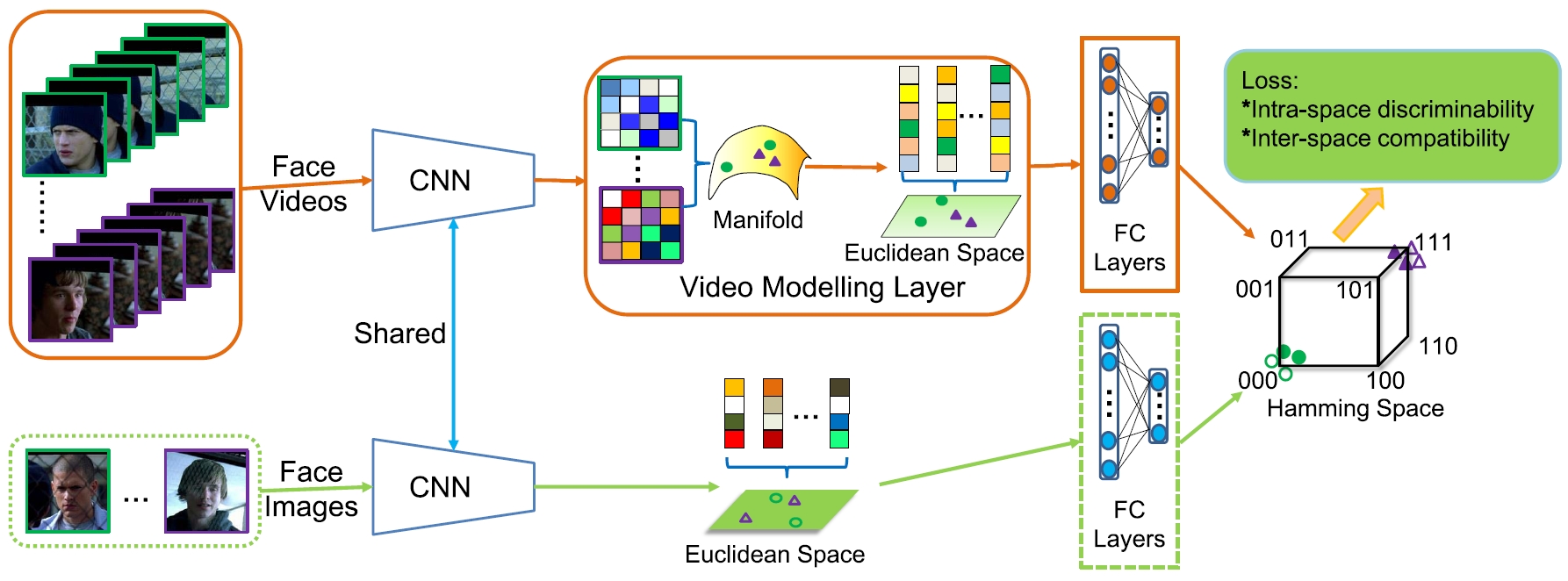
We present an end-to-end Deep Heterogeneous Hashing (DHH) method that integrates three stages including image feature learning, video modeling, and heterogeneous hashing in a single framework, to learn unified binary codes for both face images and videos. To tackle the key challenge of hashing on manifold, a well-studied Riemannian kernel mapping is employed to project data (i.e. covariance matrices) into Euclidean space and thus enables to embed the two heterogeneous representations into a common Hamming space, where both intra-space discriminability and inter-space compatibility are considered. To perform network optimization, the gradient of the kernel mapping is innovatively derived via structured matrix backpropagation in a theoretically principled way.
-
Shishi Qiao, Ruiping Wang, Shiguang Shan, Xilin Chen, “Deep Heterogeneous Hashing for Face Video Retrieval,” IEEE Transactions on Image Processing, vol. 29, no. 1, pp. 1299-1312, Dec. 2020. [Supplemental Material] [code]
|
|
|
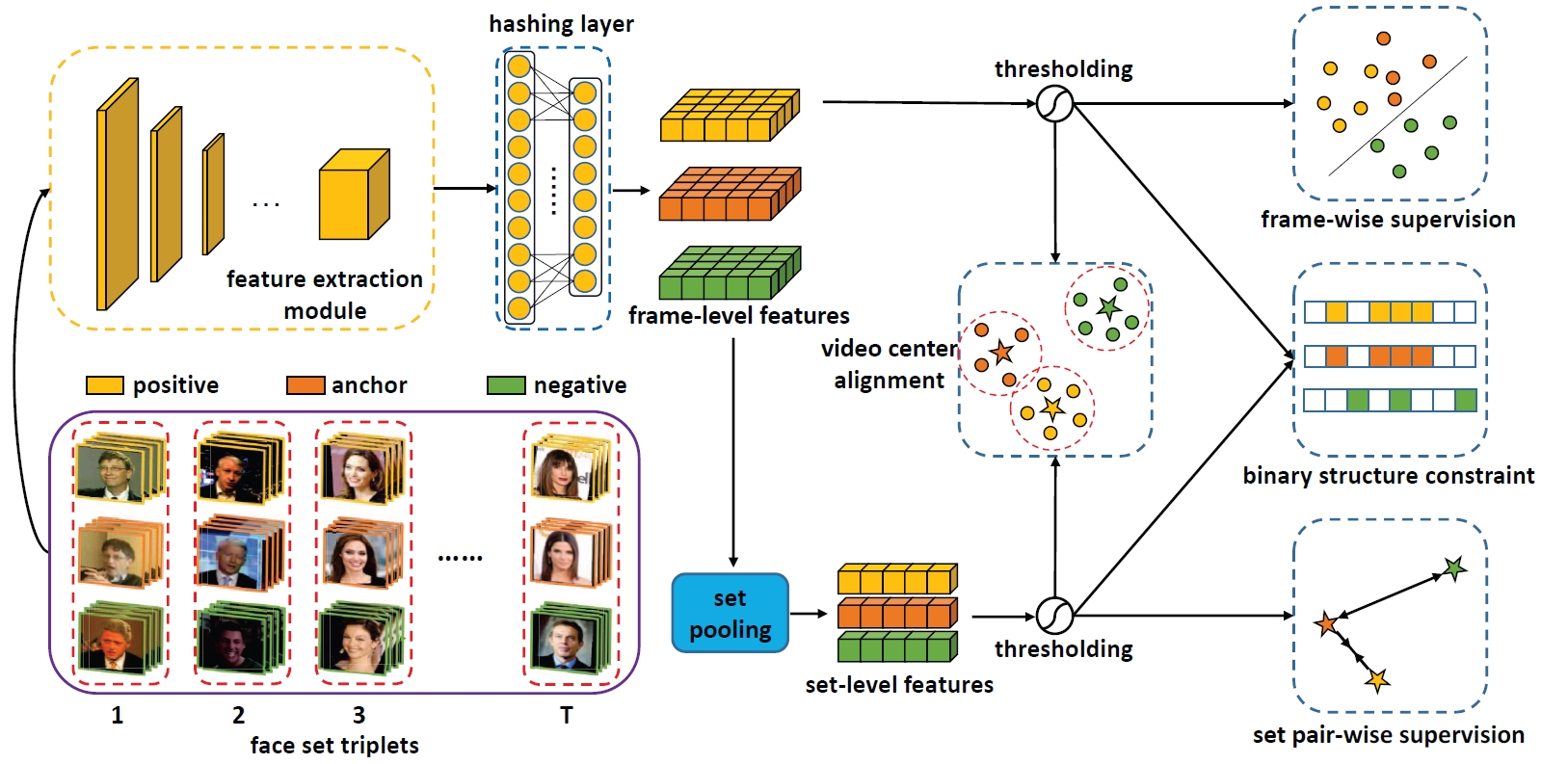
Hybrid Video and Image Hashing (HVIH)
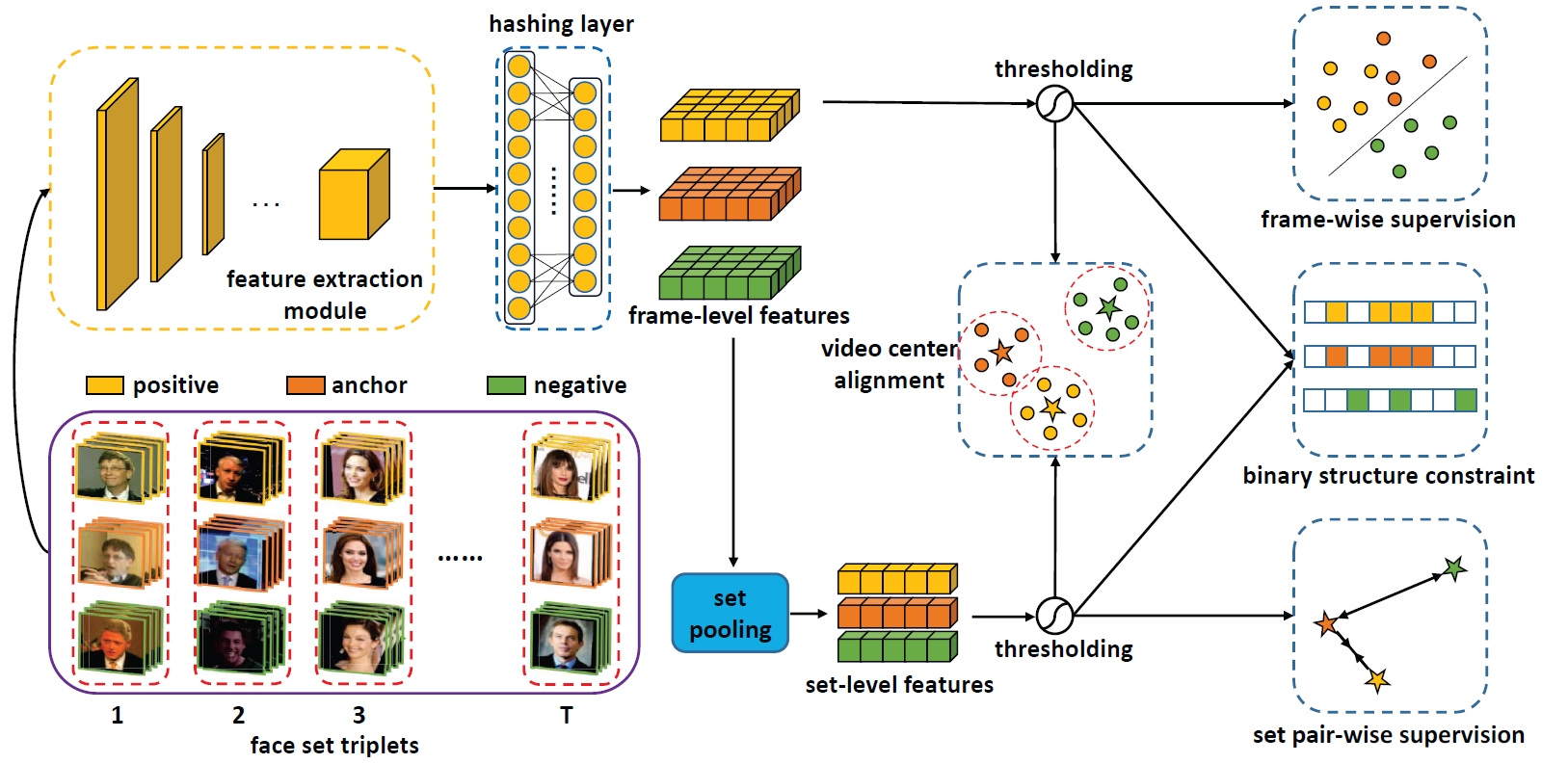
We propose Hybrid Video and Image Hashing (HVIH) to learn more effective binary codes for face videos. Specifically, we fully exploit the dense frame features rather than simply discarding them after the video level fusion and jointly optimize binary codes for the video and its composed frames in adapted supervised manners. To achieve more robust video representation, we introduce a module of video center alignment to ensure the binary codes location of the video and its frames to be as compact and consistent as possible in the Hamming space, which naturally facilitates both tasks of video-to-video retrieval and image-to-video retrieval.
-
Ruikui Wang, Shishi Qiao, Ruiping Wang, Shiguang Shan, Xilin Chen, “Hybrid Video and Image Hashing for Robust Face Retrieval,” 15th IEEE International Conference on Automatic Face and Gesture Recognition (FG 2020), pp. 168–175, Buenos Aires, Argentina, Nov. 16-20, 2020. [code]
|
|
|
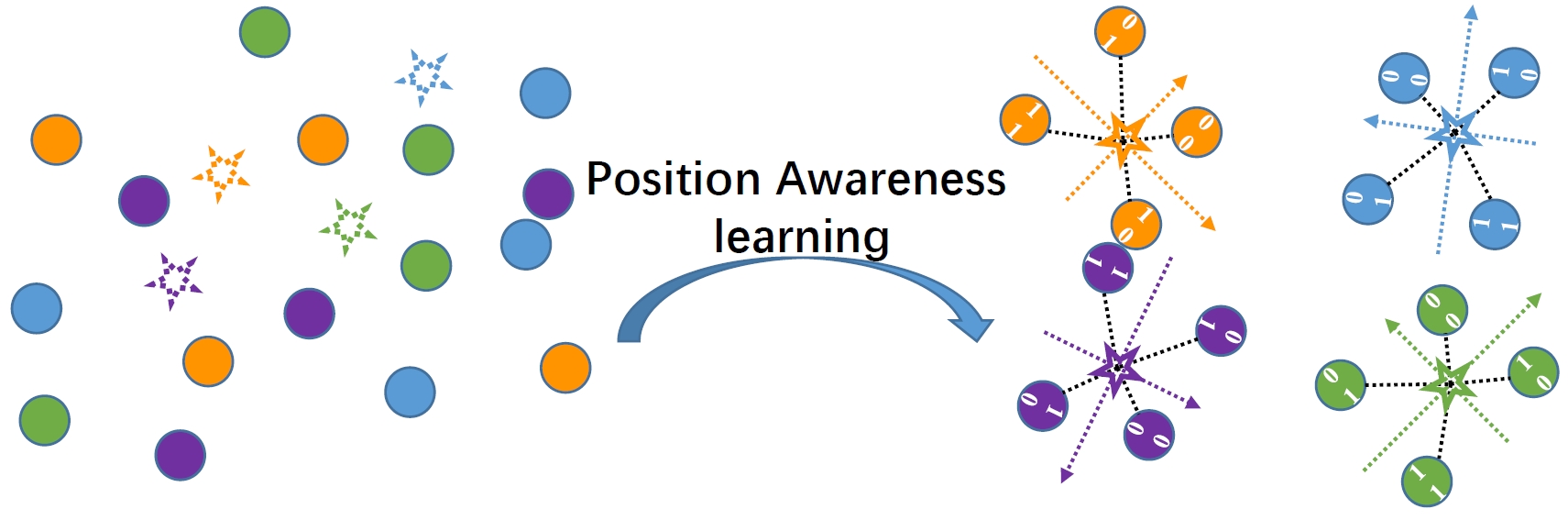
Deep Position-Aware Hashing (DPAH)
We propose Deep Position-Aware Hashing (DPAH) to ensure continuous semantic similarity in Hamming space by modeling global positional relationship. Specifically, we introduce a set of learnable class centers as the global proxies to represent the global information and generate discriminative binary codes by constraining the distance between data points and class centers. In addition, in order to reduce the information loss caused by relaxing the binary codes to real-values in optimization, we propose kurtosis loss (KT loss) to handle the distribution of real-valued features before thresholding to be double-peak, and then enable the real-valued features to be more binary-like.
-
Ruikui Wang, Ruiping Wang, Shishi Qiao, Shiguang Shan, Xilin Chen, “Deep Position-Aware Hashing for Semantic Continuous Image Retrieval,” IEEE Winter Conference of Applications on Computer Vision (WACV 2020), pp. 2493–2502, Aspen, CO, Mar. 2-5, 2020. [Supplemental Material] [code]
|
|
|
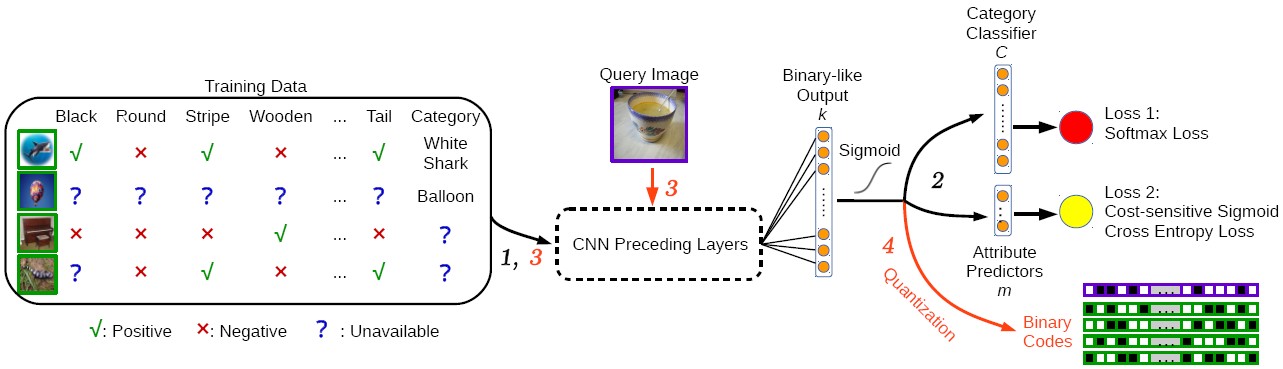
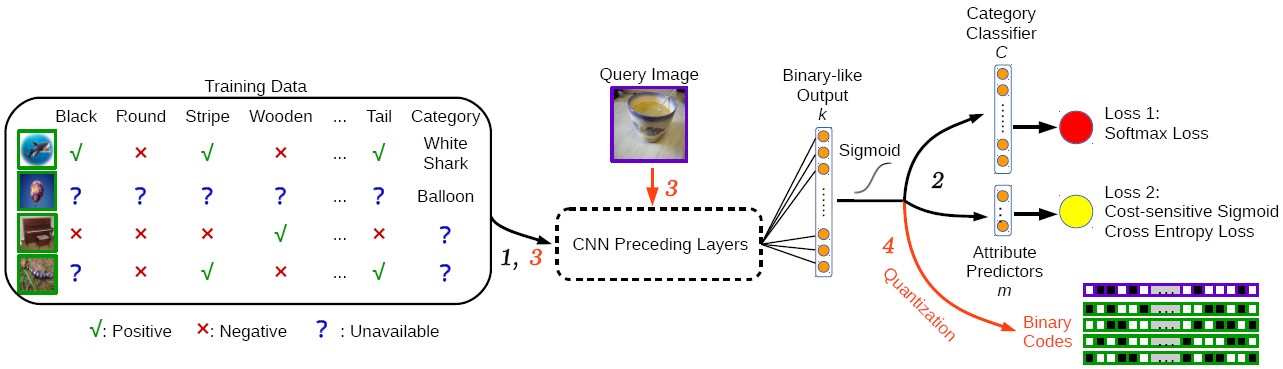
Dual Purpose Hashing (DPH)
We propose a unified framework to address multiple realistic image retrieval tasks concerning both category and attributes by jointly preserving the category and attribute similarities. Since images with both category and attribute labels are scarce, our method is designed to take the abundant partially labelled images on the Internet as training inputs. With such a framework, the binary codes of new-coming images can be readily obtained by quantizing the network outputs of a binary-like layer, and the attributes can be recovered from the codes easily.
-
Haomiao Liu, Ruiping Wang, Shiguang Shan, Xilin Chen, “Learning Multifunctional Binary Codes for Both Category and Attribute Oriented Retrieval Tasks,” IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2017), pp. 6259-6268, Honolulu, HI, July 21-26, 2017. [Supplemental Material] [code]
-
Haomiao Liu, Ruiping Wang, Shiguang Shan, Xilin Chen, “Learning Multifunctional Binary Codes for Personalized Image Retrieval,” International Journal of Computer Vision, vol. 128, no. 8, pp. 2223–2242, Sep. 2020.
|
|
|
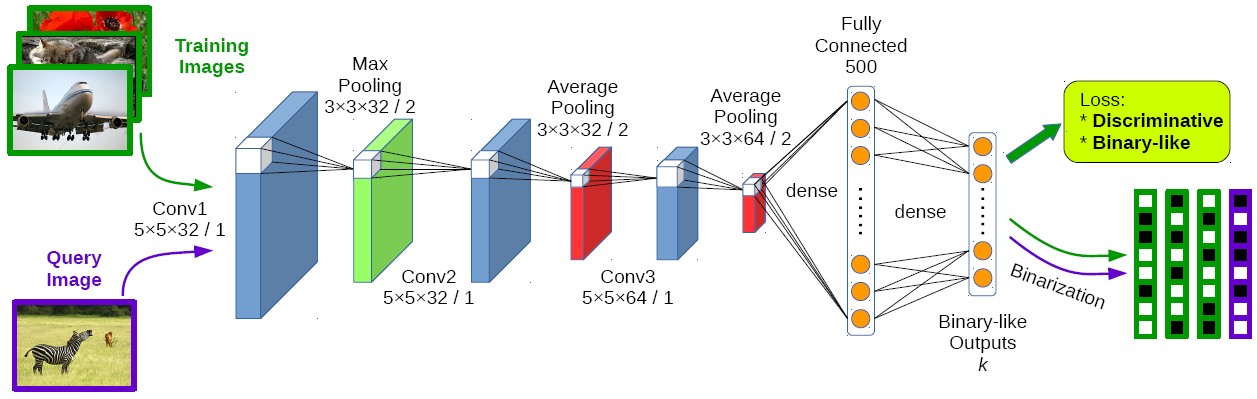
Deep Supervised Hashing (DSH)
We devise a CNN architecture that takes pairs of images (similar/dissimilar) as training inputs and encourages the output of each image to approximate discrete values (e.g. +1/-1). A loss function is elaborately designed to maximize the discriminability of the output space by encoding the supervised information from the input image pairs, and simultaneously imposing regularization on the real-valued outputs to approximate the desired discrete values.
-
Haomiao Liu, Ruiping Wang, Shiguang Shan, Xilin Chen, “Deep Supervised Hashing for Fast Image Retrieval,” IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2016), pp. 2064-2072, Las Vegas, NV, June 26-July 1, 2016. [Supplemental Material] [code]
-
Haomiao Liu, Ruiping Wang, Shiguang Shan, Xilin Chen, “Deep Supervised Hashing for Fast Image Retrieval,” International Journal of Computer Vision, vol. 127, no. 9, pp. 1217–1234, Sep. 2019.
|
|
|
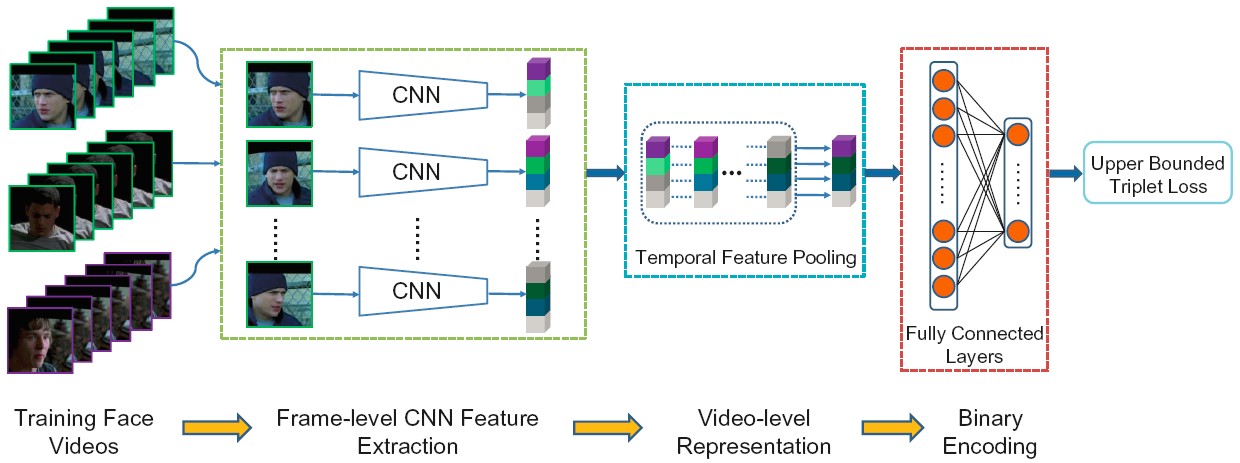
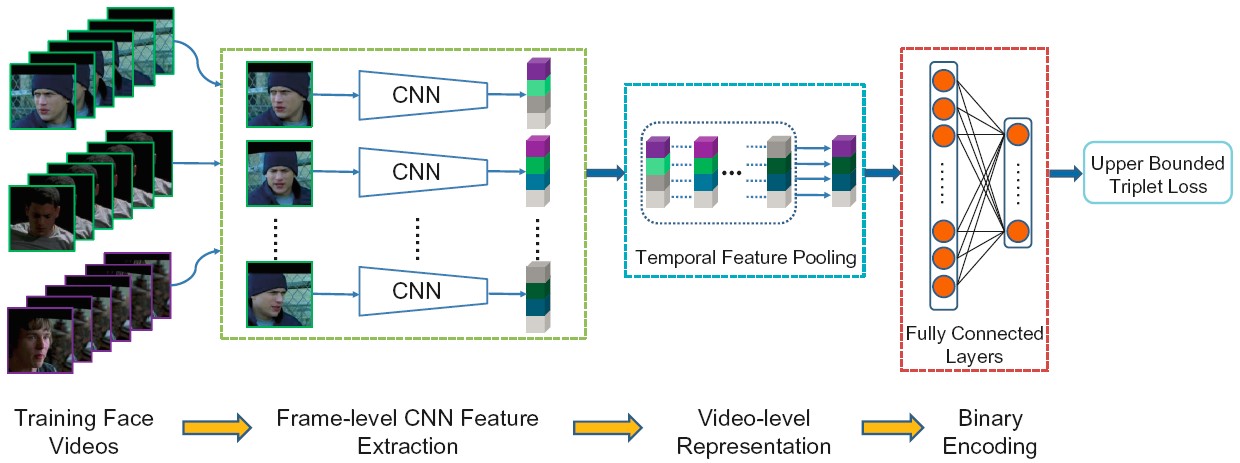
Deep Video Code (DVC)
For face video retrieval, we propose a novel Deep Video Code (DVC) method which encodes face videos into compact binary codes. Specifically, we devise a multi-branch CNN architecture that takes face videos as training inputs, models each of them as a unified representation by temporal feature pooling operation, and finally projects the high-dimensional representations into Hamming space to generate a single binary code for each video as output, where distance of dissimilar pairs is larger than that of similar pairs by a margin.
-
Shishi Qiao, Ruiping Wang, Shiguang Shan, Xilin Chen, “Deep Video Code for Efficient Face Video Retrieval,” 13th Asian Conference on Computer Vision (ACCV 2016), Part III, LNCS 10113, pp. 296-312, Nov. 20-24, 2016. [code]
-
Shishi Qiao, Ruiping Wang, Shiguang Shan, Xilin Chen, “Deep Video Code for Efficient Face Video Retrieval,” Pattern Recognition, vol. 113, pp. 1-11, May. 2021.
|

|
|
Jointly Learning Binary Code (JLBC)
To address large-scale content-based face image retrieval problem, we propose a novel binary code learning framework by jointly encoding identity discriminability and a number of facial attributes into unified binary code. In this way, the learned binary codes can be applied to not only fine-grained face image retrieval, but also facial attributes prediction, which is the very innovation of this work, just like killing two birds with one stone.
-
Yan Li, Ruiping Wang, Haomiao Liu, Huajie Jiang, Shiguang Shan, Xilin Chen, “Two Birds, One Stone: Jointly Learning Binary Code for Large-scale Face Image Retrieval and Attributes Prediction,” 15th IEEE International Conference on Computer Vision (ICCV 2015), pp. 3819-3827, Santiago, Chile, Dec. 11-18, 2015. [code]
|
|
|
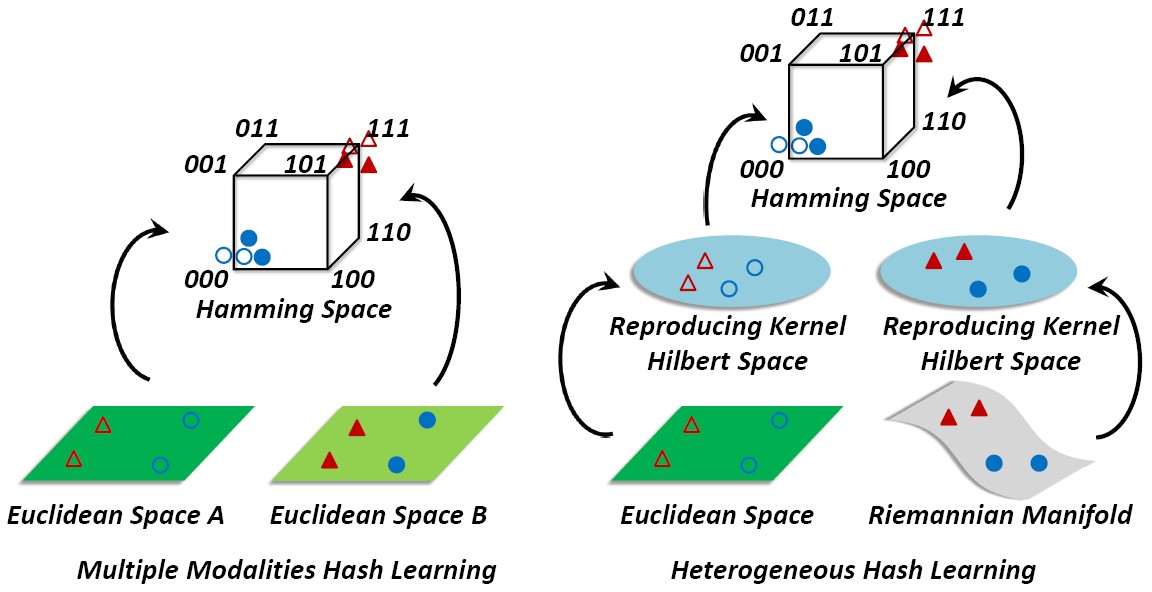
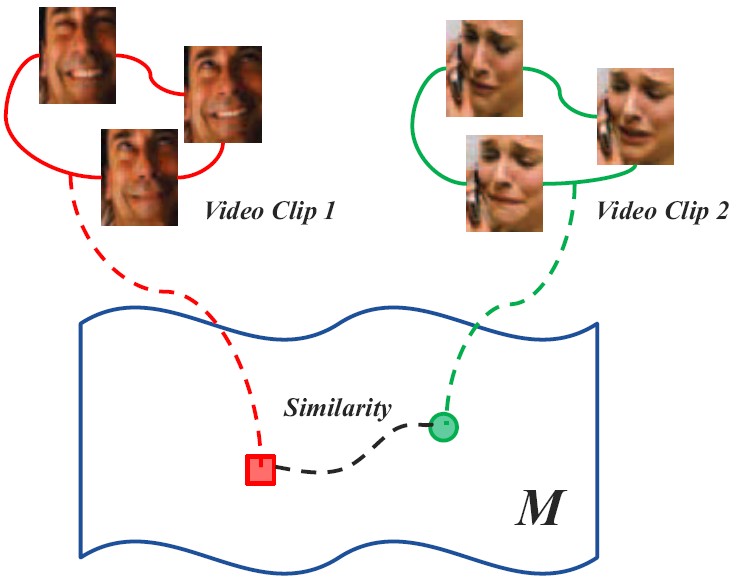
Hashing across Euclidean space and Riemannian manifold (HER)
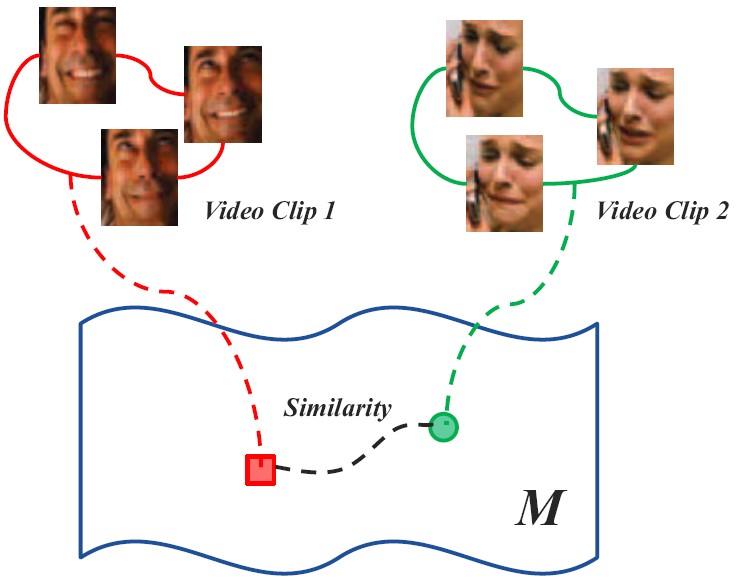
For retrieving videos of a person given his/her face image as query, we represent image as point (i.e., vector) in Euclidean space and video clip as point (e.g., covariance matrix) on Riemannian manifold, and formulate a new hashing-based retrieval problem of matching two heterogeneous representations. This work makes the first attempt to embed the two heterogeneous spaces into a common discriminant Hamming space by deriving a unified framework of Hashing across Euclidean space and Riemannian manifold (HER).
-
Yan Li, Ruiping Wang, Zhiwu Huang, Shiguang Shan, Xilin Chen, “Face Video Retrieval with Image Query via Hashing across Euclidean Space and Riemannian Manifold,” IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2015), pp. 4758-4767, Boston, MA, June 7-12, 2015. [code]
|
|
|
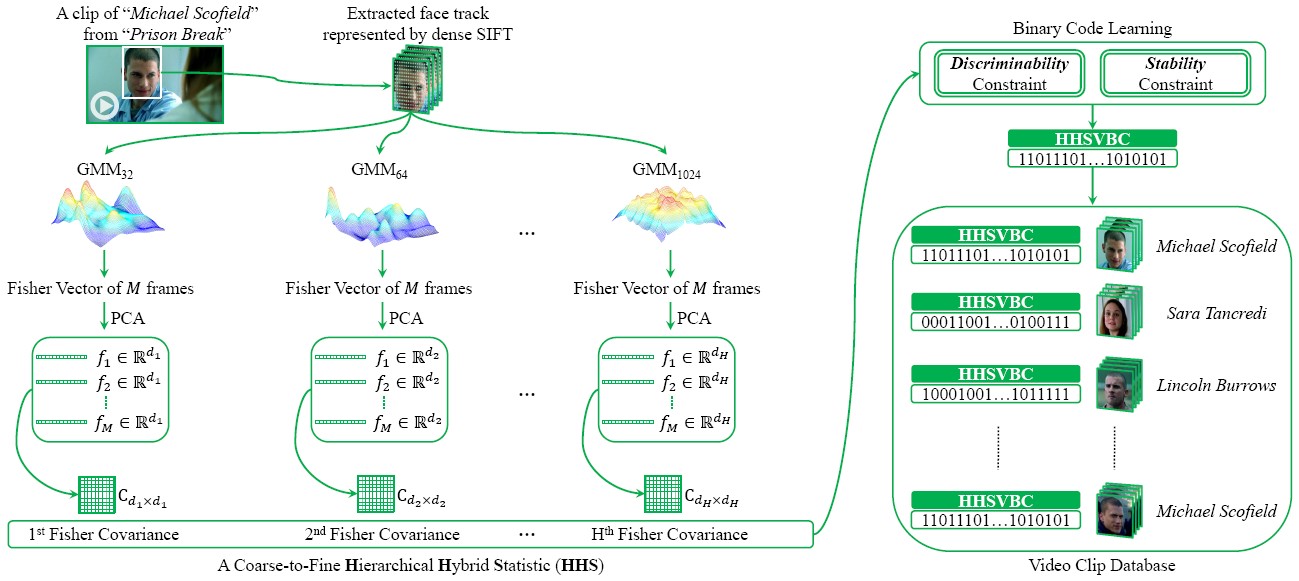
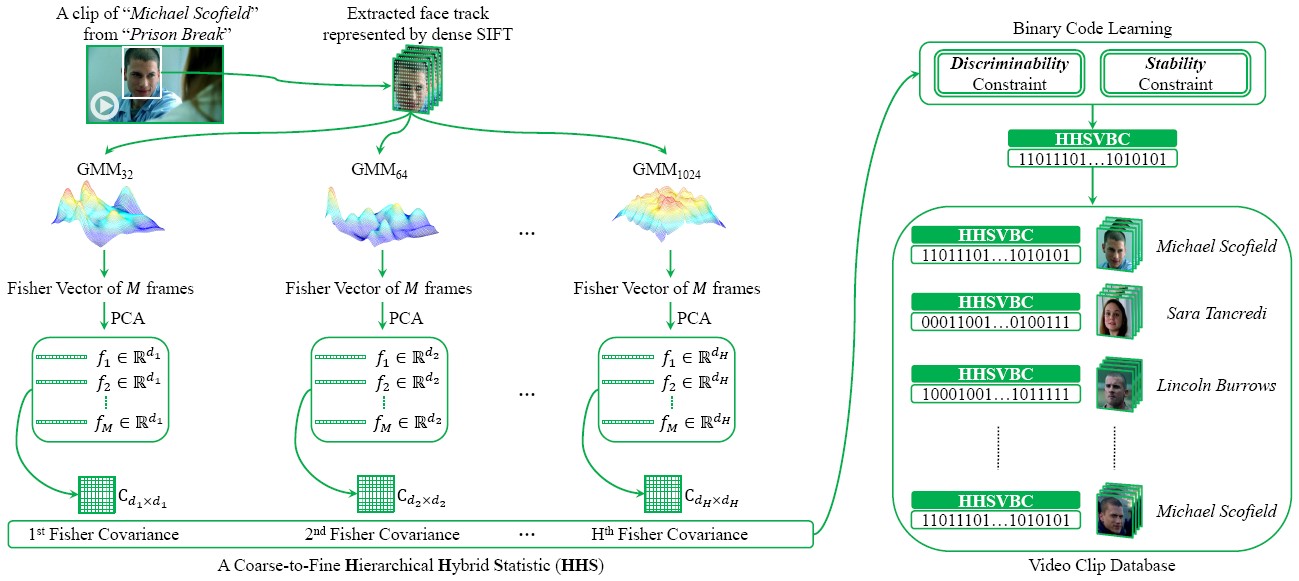
Hierarchical Hybrid Statistic (HHS)
We propose a compact and discriminative binary representation for video. Our method first utilizes different parameterized Fisher Vectors (FVs) as frame representation that can encode multi-granularity low level variation within the frame, and then models the video by its frame covariance matrix to capture high level variation among frames. To incorporate discriminative information and obtain more compact video signature, the high-dimensional representation is further encoded to a much lower-dimensional binary vector.
-
Yan Li, Ruiping Wang, Shiguang Shan, Xilin Chen, “Hierarchical Hybrid Statistic based Video Binary Code and Its Application to Face Retrieval in TV-Series,” 11th IEEE International Conference on Automatic Face and Gesture Recognition (FG 2015), Ljubljana, Slovenia, May 4-8, 2015. (Oral)
|
|
|
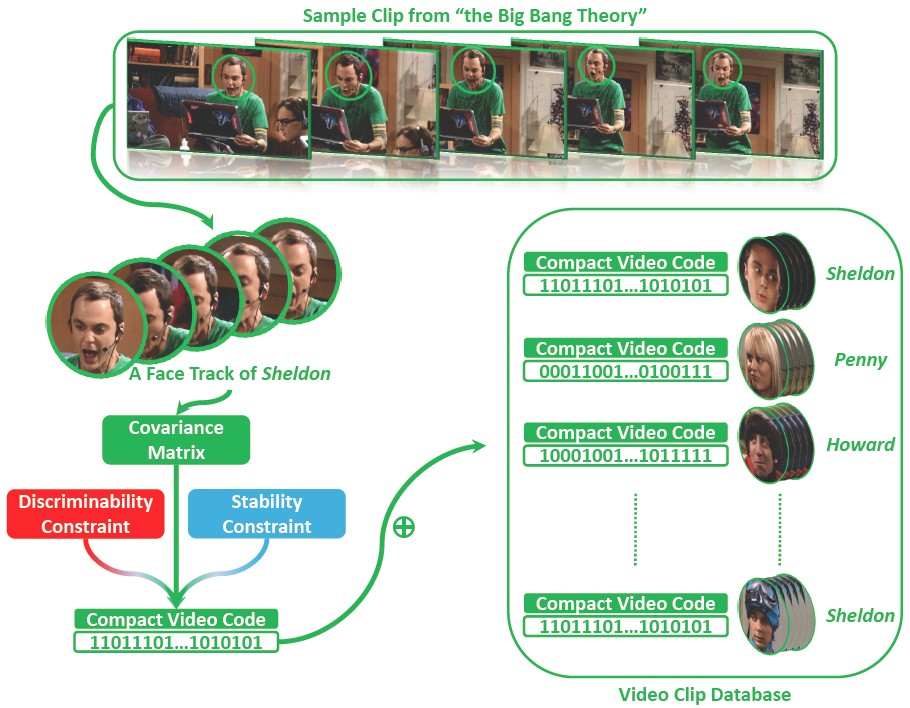
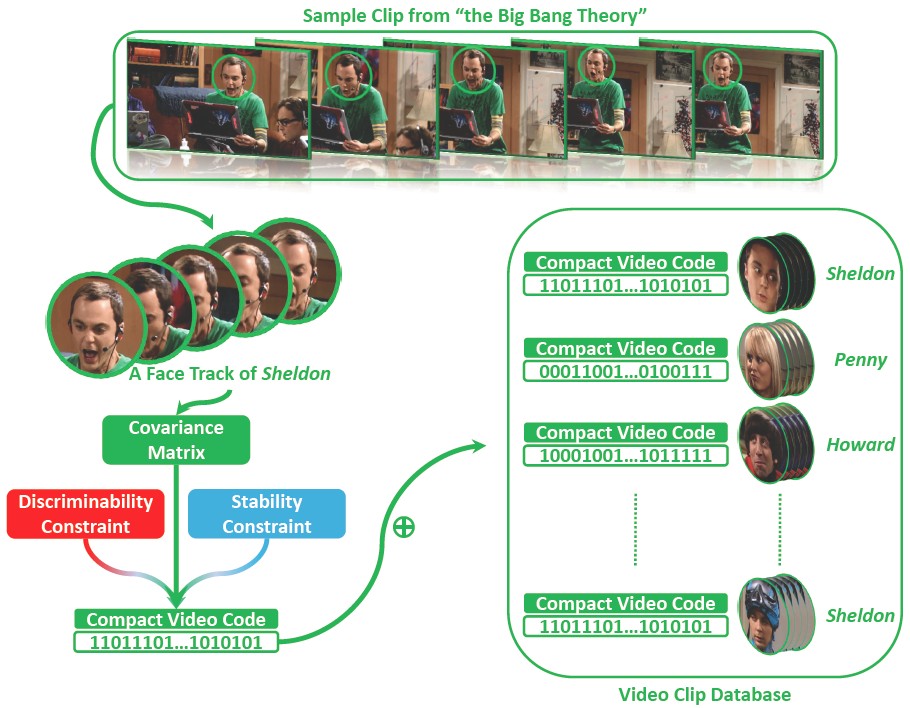
Compact Video Code (CVC)
We propose a compact and discriminative representation for the huge body of video data, named Compact Video Code (CVC). Our method first models the video clip by its sample (i.e., frame) covariance matrix to capture the video data variations in a statistical manner. To incorporate discriminative information and obtain more compact video signature, the high-dimensional covariance matrix is further encoded as a much lower-dimensional binary vector, which finally yields the proposed CVC.
-
Yan Li, Ruiping Wang, Zhen Cui, Shiguang Shan, Xilin Chen, “Compact Video Code and Its Application to Robust Face Retrieval in TV-Series,” 25th British Machine Vision Conference (BMVC 2014), Nottingham, UK, Sep. 1-5, 2014. [code]
-
Yan Li, Ruiping Wang, Zhen Cui, Shiguang Shan, Xilin Chen, “Spatial Pyramid Covariance based Compact Video Code for Robust Face Retrieval in TV-series,” IEEE Transactions on Image Processing, vol. 25, no. 12, pp. 5905-5919, Dec. 2016.
|
Facial Expression Analysis (Apr. 2012 - Dec. 2015)
Publication:
|
|
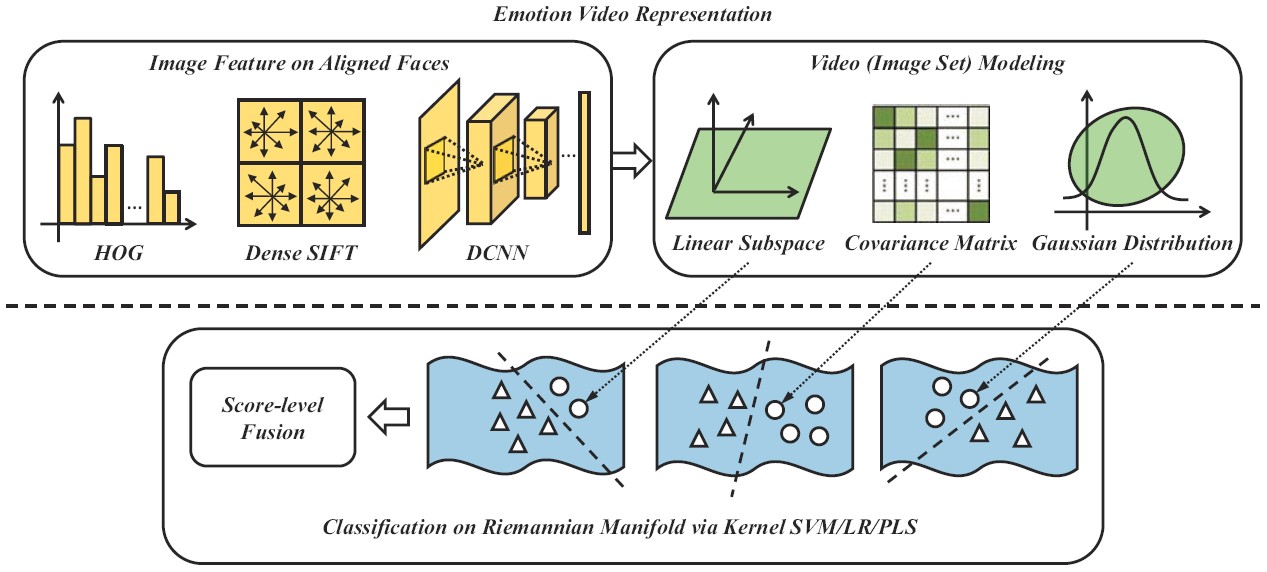
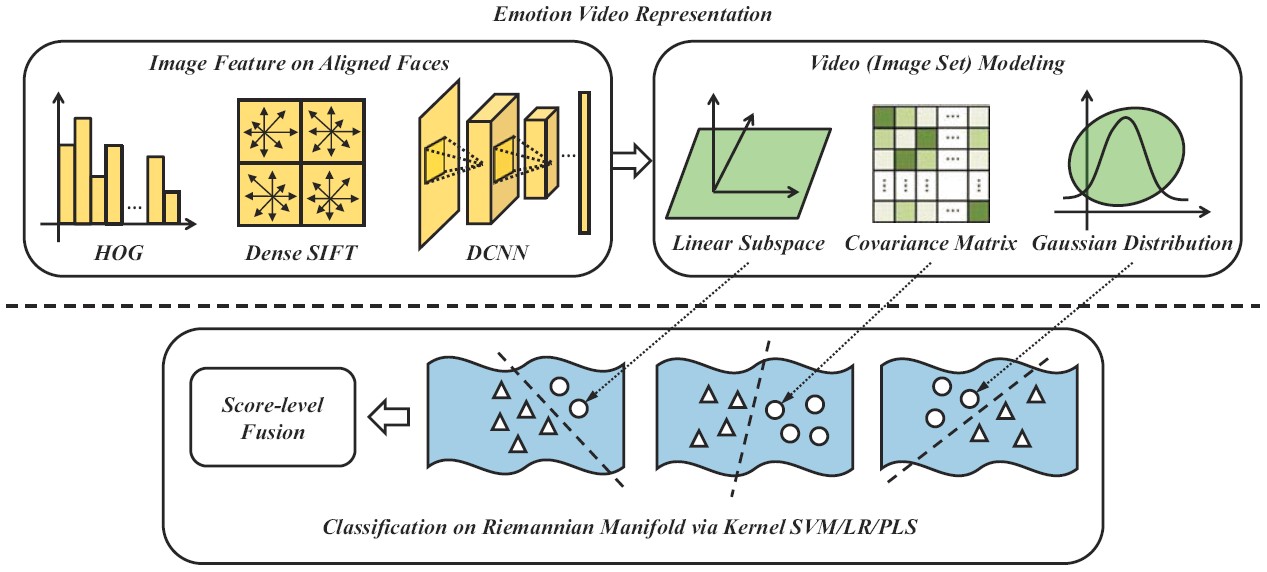
Multiple Kernel Methods on Riemannian Manifold
Each video clip can be represented by three types of image set models. Different Riemannian kernels are employed on these set models correspondingly for similarity/distance measurement. For classification, three types of classifiers are investigated for comparisons. Finally, an optimal fusion of classifiers learned from different kernels and modalities (video and audio) is conducted at the decision level.
-
Mengyi Liu, Ruiping Wang, Shaoxin Li, Shiguang Shan, Zhiwu Huang, Xilin Chen, “Combining Multiple Kernel Methods on Riemannian Manifold for Emotion Recognition in the Wild,” 16th ACM International Conference on Multimodal Interaction (ICMI 2014), pp. 494-501, Istanbul, Turkey, Nov. 12-16, 2014. [code] [Presentation] (First Position Winner Award in EmotiW2014 Challenge)
|
|
|
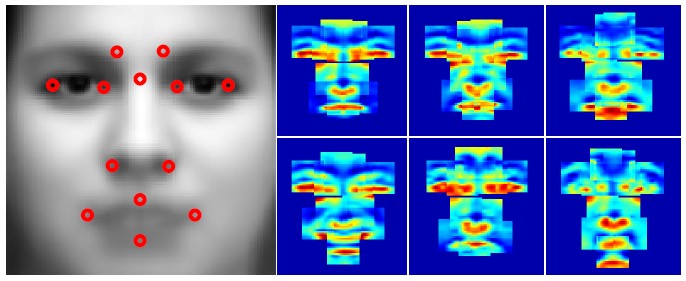
Deeply Learning Deformable Facial Action Parts Model
Expressions are facial activities invoked by sets of muscle motions, which would give rise to large variations in appearance mainly around facial parts. Therefore, for visual-based expression analysis, localizing the action parts and encoding them effectively become two essential but challenging problems. To take them into account jointly for expression analysis, in this paper, we propose to adapt 3D Convolutional Neural Networks (3D CNN) with deformable action parts constraints.
-
Mengyi Liu, Shaoxin Li, Shiguang Shan, Ruiping Wang, Xilin Chen, “Deeply Learning Deformable Facial Action Parts Model for Dynamic Expression Analysis,” 12th Asian Conference on Computer Vision (ACCV 2014), Singapore, Nov. 1-5, 2014, Part IV, LNCS 9006, pp. 143–157, 2015.
|
|
|
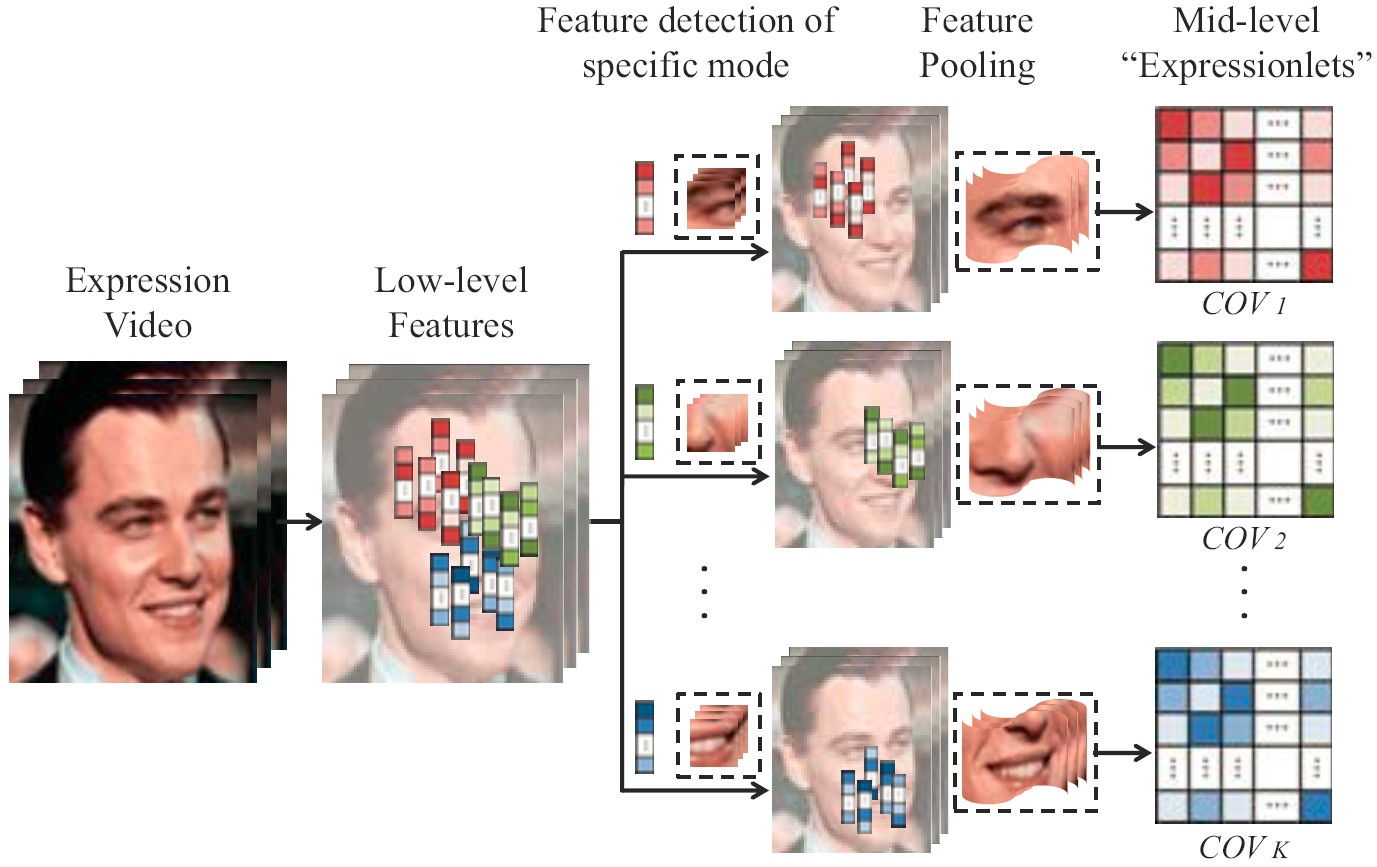
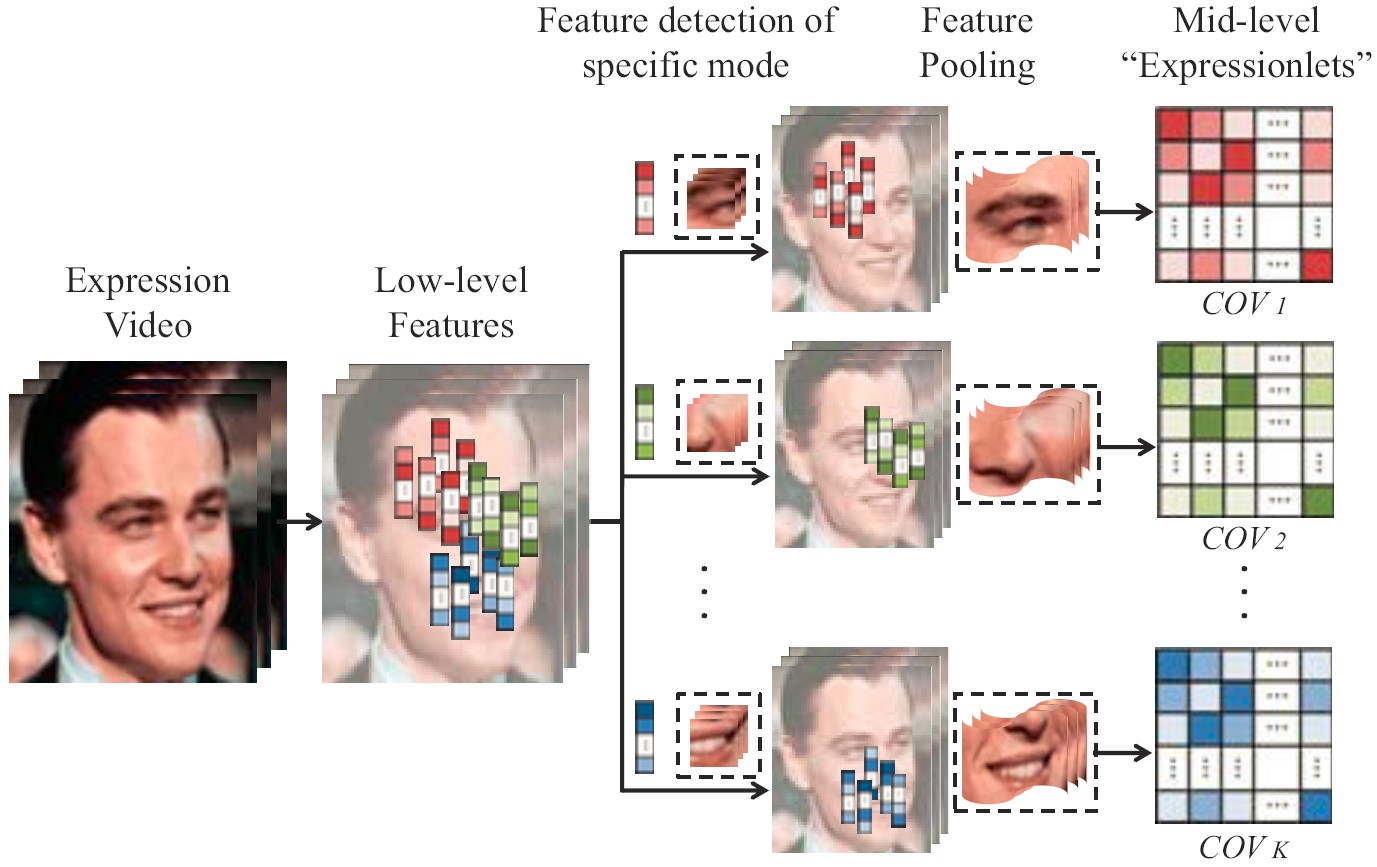
Learning Expressionlets on Spatio-Temporal Manifold
For dynamic expression recognition, two key issues, temporal alignment and semantics-aware dynamic representation, must be taken into account. In this paper, we attempt to solve both problems via manifold modeling of videos based on a novel mid-level representation, i.e. expressionlet.
-
Mengyi Liu, Shiguang Shan, Ruiping Wang, Xilin Chen, “Learning Expressionlets on Spatio-Temporal Manifold for Dynamic Facial Expression Recognition,” IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2014), pp. 1749-1756, Columbus, Ohio, June 23-28, 2014. [code]
-
Mengyi Liu, Shiguang Shan, Ruiping Wang, Xilin Chen, “Learning Expressionlets via Universal Manifold Model for Dynamic Facial Expression Recognition,” IEEE Transactions on Image Processing, vol. 25, no. 12, pp. 5920-5932, Dec. 2016.
|
|
|
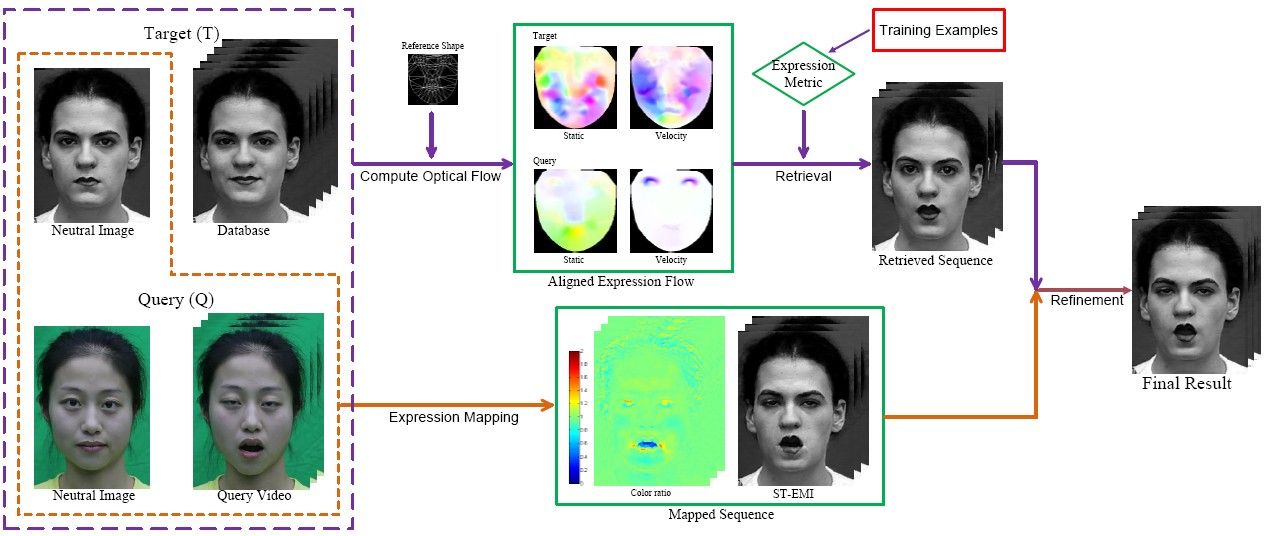
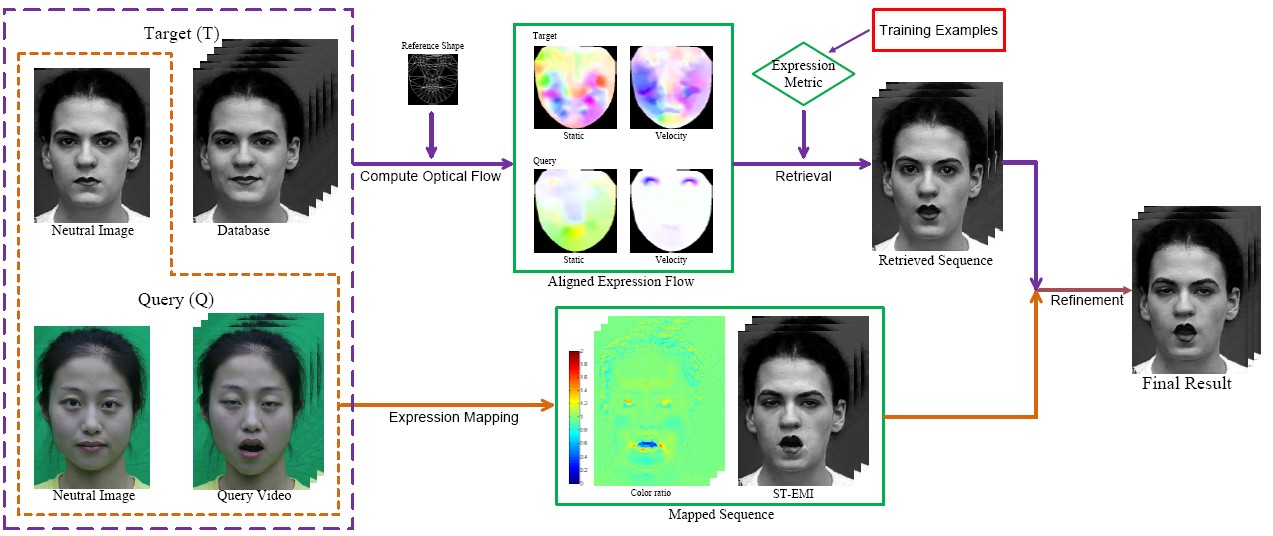
Facial Expression Retargeting in Video
This paper presents a data-driven approach for facial expression retargeting in video, i.e., synthesizing a face video of a target subject that mimics the expressions of a source subject in the input video. Our approach takes advantage of a pre-existing facial expression database of the target subject to achieve realistic synthesis.
-
Kai Li, Qionghai Dai, Ruiping Wang, Yebin Liu, Feng Xu, Jue Wang, “A Data-driven Approach for Facial Expression Retargeting in Video,” IEEE Transactions on Multimedia, vol. 16, no. 2, pp. 299-310, Feb. 2014.
|
|
|
PLS on Grassmannian Manifold for Emotion Recognition
We propose a method for video-based human emotion recognition. For each video clip, all frames are represented as an image set, which can be modeled as a linear subspace to be embedded in Grassmannian manifold. After feature extraction, Class-specific One-to-Rest Partial Least Squares (PLS) is learned on video and audio data respectively to distinguish each class from the other confusing ones.
-
Mengyi Liu, Ruiping Wang, Zhiwu Huang, Shiguang Shan, Xilin Chen, “Partial Least Squares Regression on Grassmannian Manifold for Emotion Recognition,” 15th ACM International Conference on Multimodal Interaction (ICMI 2013), pp. 525-530, Sydney, Australia, Dec. 9-13, 2013. [code] [Presentation] (Second Runner-Up Award in EmotiW2013 Challenge)
|
Face Recognition (Aug. 2011 - Dec. 2013)
Publication:
|
|
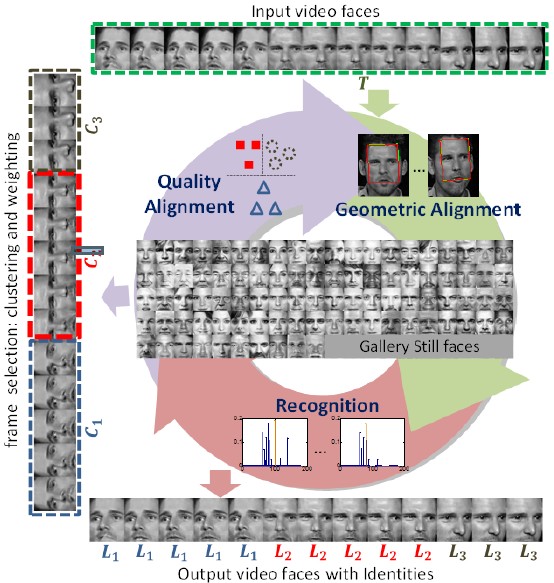
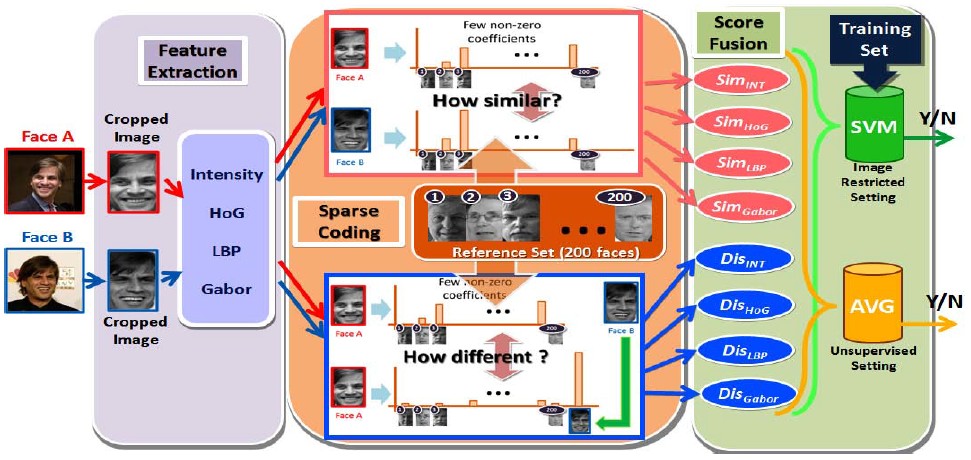
Coupling Alignments with Recognition (CAR)
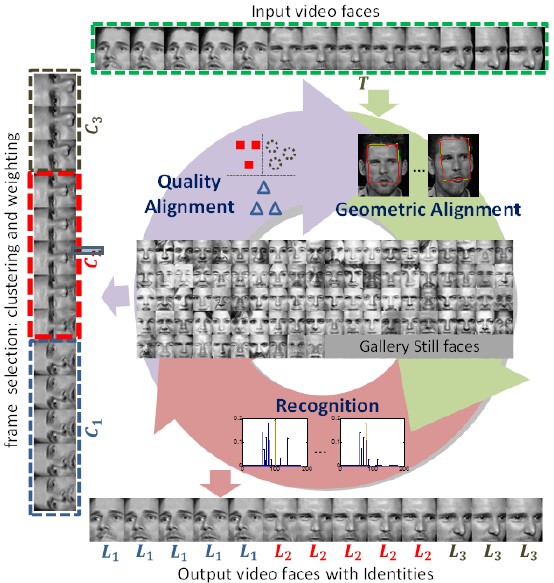
We discover that the interactions among the three tasks – quality alignment, geometric alignment and face recognition – can benefit from each other, thus should be performed jointly. With this in mind, we propose a Coupling Alignments with Recognition (CAR) method to tightly couple these tasks via low-rank regularized sparse representation in a unified framework. Our method makes the three tasks promote mutually by a joint optimization in an Augmented Lagrange Multiplier routine.
-
Zhiwu Huang, Xiaowei Zhao, Shiguang Shan, Ruiping Wang, Xilin Chen, “Coupling Alignments with Recognition for Still-to-Video Face Recognition,” 14th IEEE International Conference on Computer Vision (ICCV 2013), pp. 3296-3303, Sydney, Australia, Dec. 3-6, 2013.
|
|
|
Face Verification Using Sparse Representations
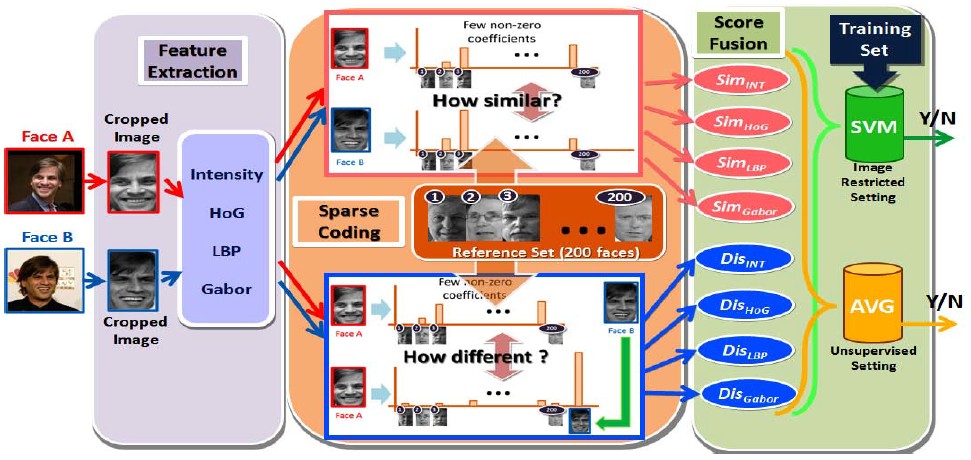
We propose a face verification framework using sparse representations that integrates two ways of employing sparsity. Given an image pair (A,B) and a dictionary D, for image A(B), we generate two sparse codes, one by using the original dictionary and the other by adding B(A) into D as an augmented dictionary. The correlation of the sparse codes is referred to as the similarity/dissimilarity score.
-
Huimin Guo, Ruiping Wang, Jonghyun Choi, Larry S. Davis, “Face Verification Using Sparse Representations,” IEEE Computer Society Workshop on Biometrics (BIOM 2012, in conjunction with CVPR), pp. 37-44, Providence, Rhode Island, June 16-21, 2012.
|
Image Set Classification (Jun. 2007 - Dec. 2017)
Publication:
|
|
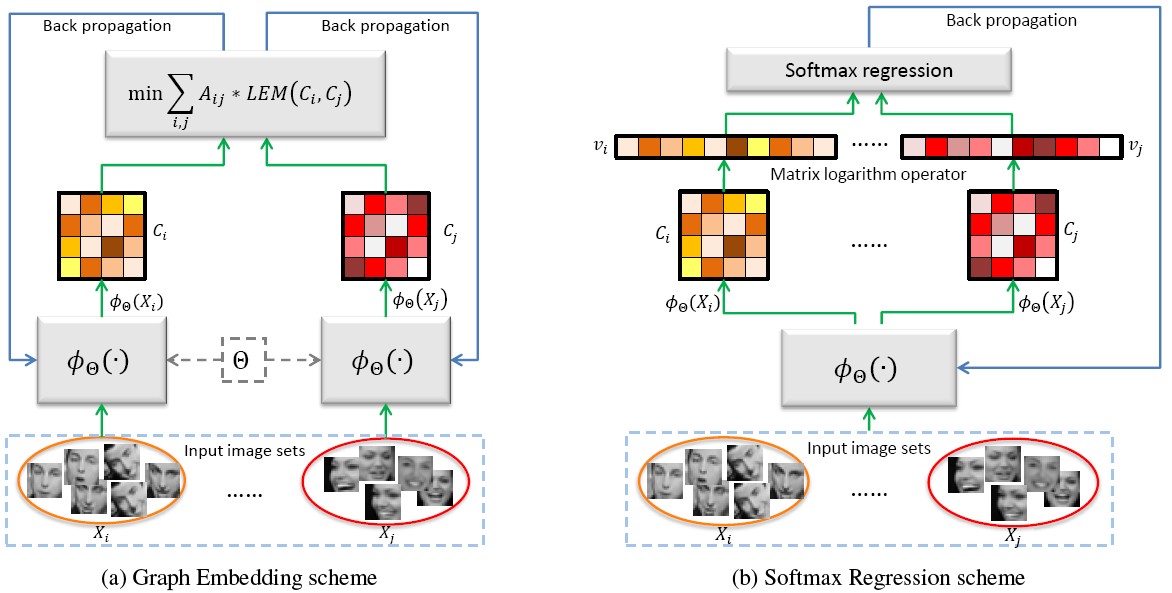
Discriminative Covariance oriented Representation Learning (DCRL)
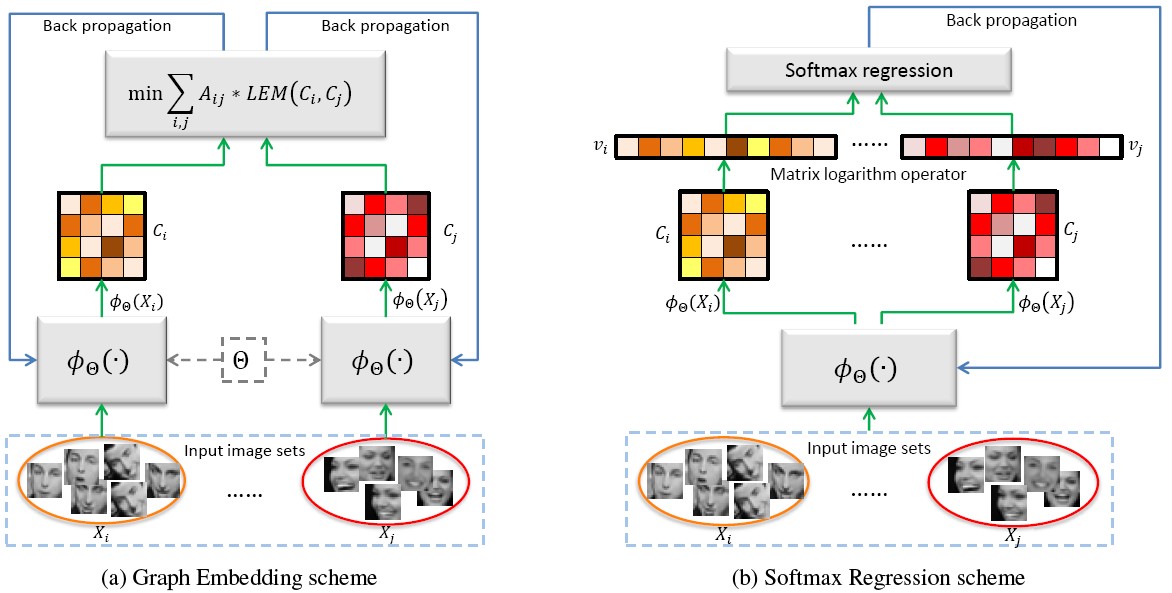
For face recognition with image sets, it remains a research gap to learn better image representations which can closely match the subsequent image set modeling and classification. Taking sample covariance matrix as set model, we present a DCRL framework to bridge the above gap. The framework constructs a feature learning network (e.g. a CNN) to project the face images into a target representation space, and the network is trained towards the goal that the set covariance matrix calculated in the target space has maximum discriminative ability. We elaborately design two learning schemes, i.e., the Graph Embedding scheme and the Softmax Regression scheme.
-
Wen Wang, Ruiping Wang, Shiguang Shan, Xilin Chen, “Discriminative Covariance Oriented Representation Learning for Face Recognition with Image Sets,” IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2017), pp. 5749-5758, Honolulu, HI, July 21-26, 2017. [Supplemental Material] [code]
|
|
|
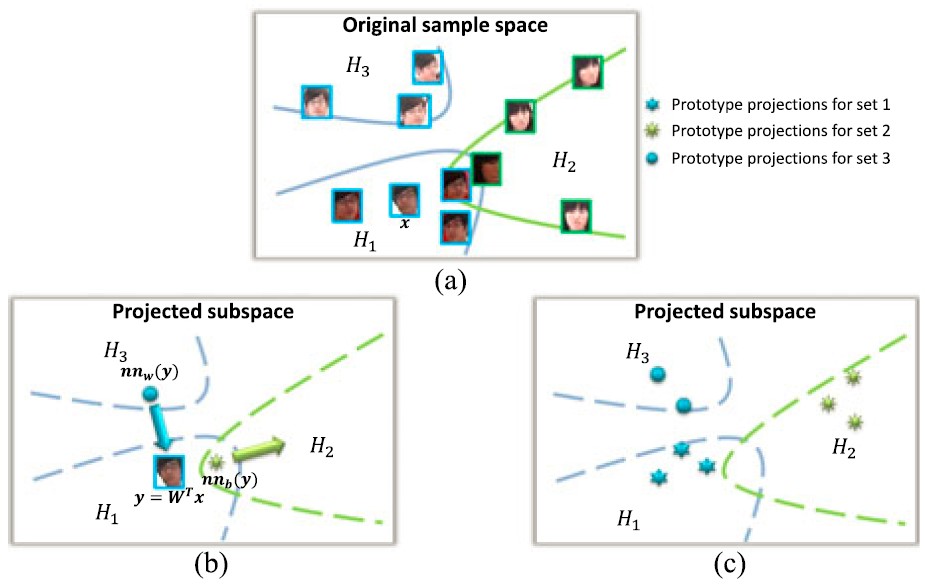
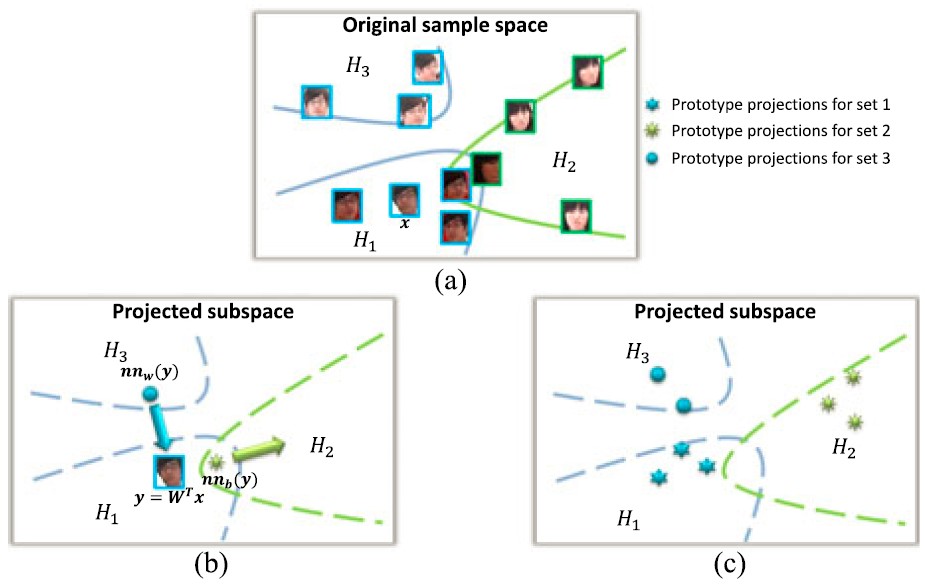
Prototype Discriminative Learning (PDL)
We present a novel Prototype Discriminative Learning (PDL) method to solve the problem of face image set classification. We aim to simultaneously learn a set of prototypes for each image set and a linear discriminative transformation to make projections on the target subspace satisfy that each image set can be optimally classified to the same class with its nearest neighbor prototype.
-
Wen Wang, Ruiping Wang, Shiguang Shan, Xilin Chen, “Prototype Discriminative Learning for Face Image Set Classification,” 13th Asian Conference on Computer Vision (ACCV 2016), Part III, LNCS 10113, pp. 344-360, Nov. 20-24, 2016. [code]
-
Wen Wang, Ruiping Wang, Shiguang Shan, Xilin Chen, “Prototype Discriminative Learning for Image Set Classification,” IEEE Signal Processing Letters, vol. 24, no. 9, pp. 1318-1322, Sep. 2017. [Supplemental Material]
|
|
|
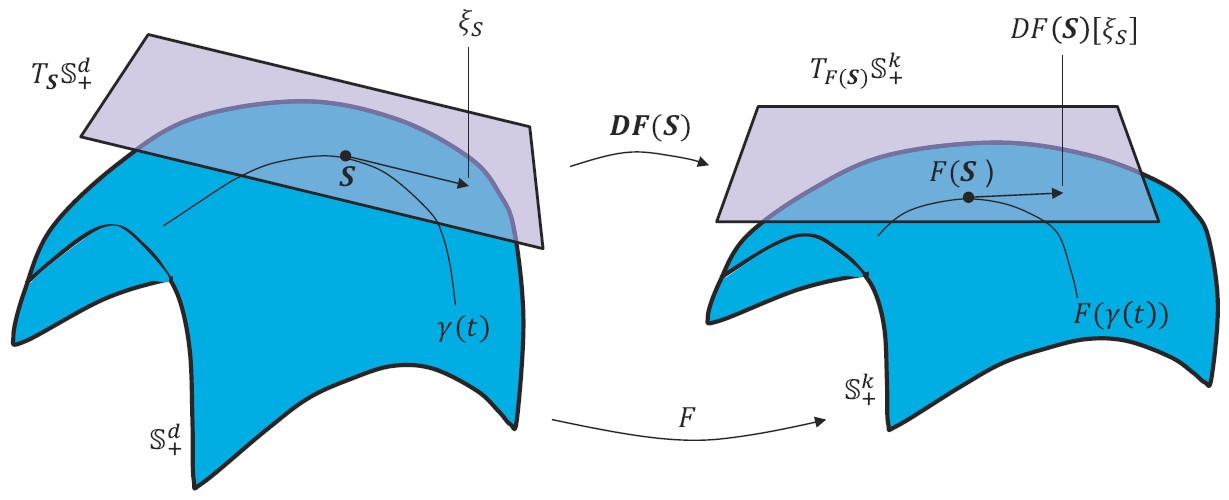
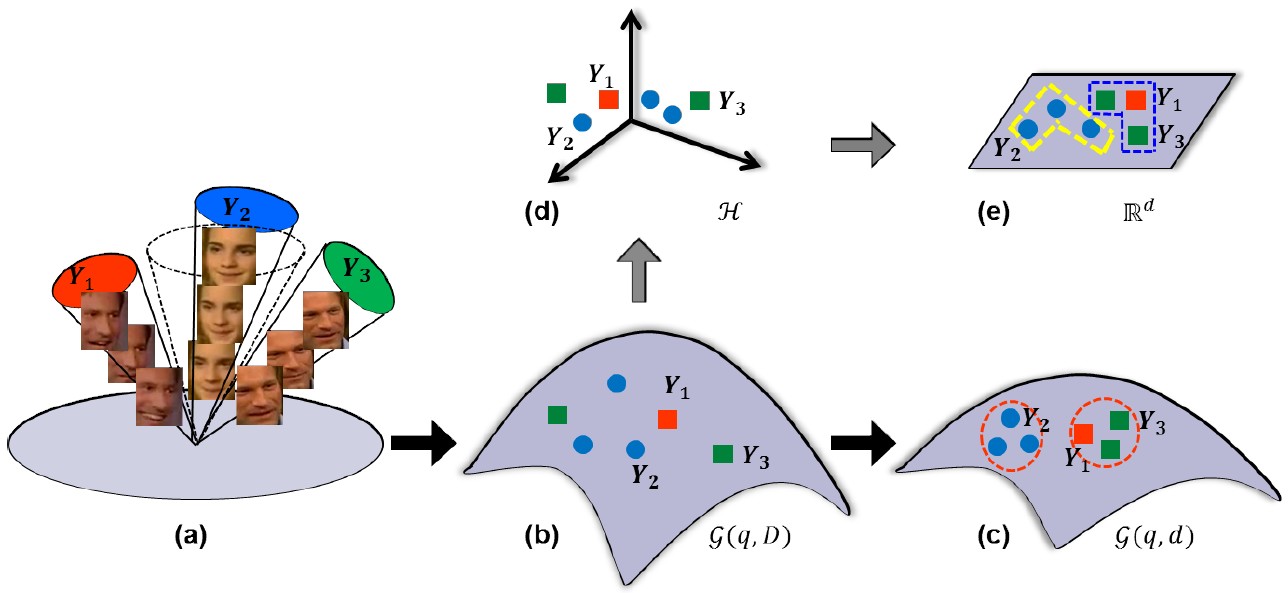
Log-Euclidean Metric Learning (LEML)
The manifold of Symmetric Positive Definite (SPD) matrices has been successfully used for data representation in image set classification. By endowing the SPD manifold with Log-Euclidean Metric, existing methods typically work on vector-forms of SPD matrix logarithms. To overcome this limitation, we propose a novel metric learning approach to work directly on logarithms of SPD matrices. Specifically, our method aims to learn a tangent map that can directly transform the matrix logarithms from the original tangent space to a new tangent space of more discriminability.
-
Zhiwu Huang, Ruiping Wang, Shiguang Shan, Xianqiu Li, Xilin Chen, “Log-Euclidean Metric Learning on Symmetric Positive Definite Manifold with Application to Image Set Classification,” The 32nd International Conference on Machine Learning (ICML 2015), pp. 720-729, Lille, France, July 6-11, 2015. [code]
|
|
|
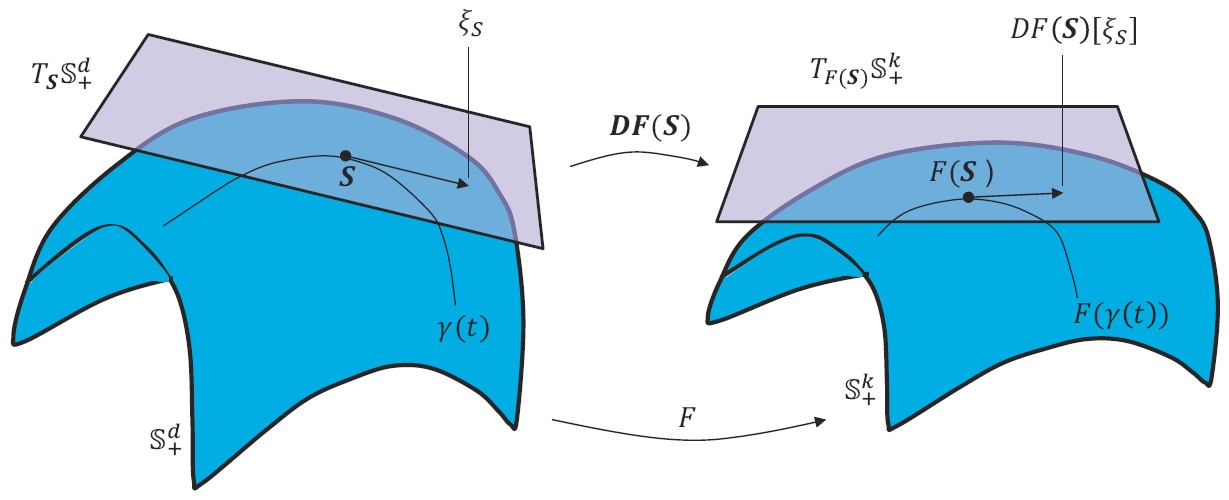
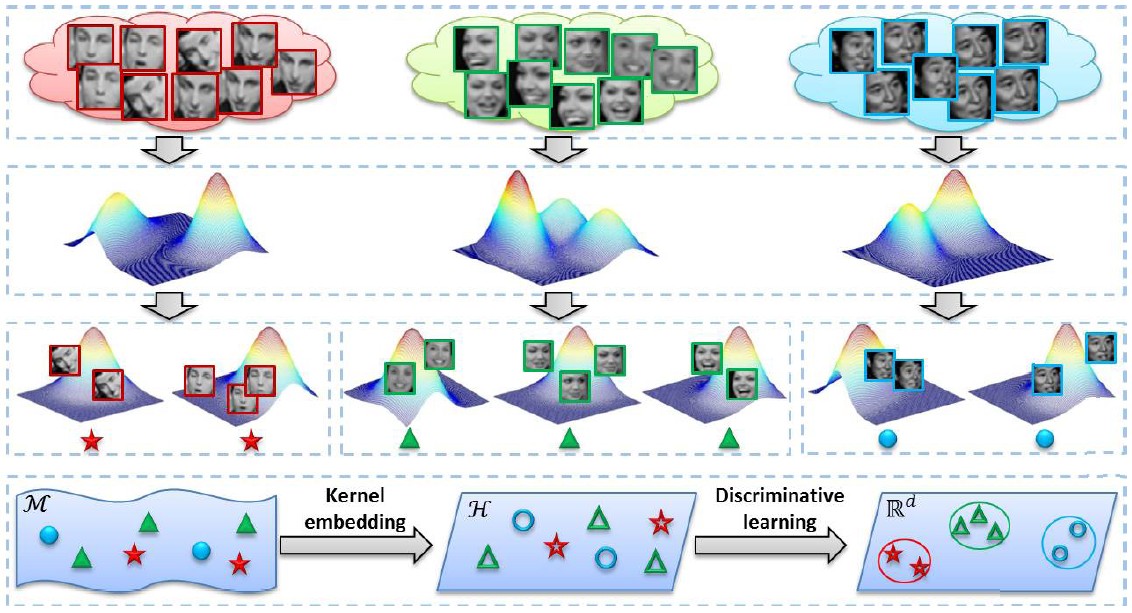
Projection Metric Learning (PML)
By representing videos(/image sets) as linear subspaces lying on Grassmann manifold, recent studies have proposed to embed the Grassmann manifold into a high-D kernel Hilbert space by exploiting the Project Metric. To overcome the limitations from kernel-based methods, e.g., implicit map and high computational cost, we propose a novel method to learn the Projection Metric directly on Grassmann manifold rather than in Hilbert space. Our method can be regarded as performing a geometry-aware dimensionality reduction from the original Grassmann manifold to a lower-D, more discriminative one.
-
Zhiwu Huang, Ruiping Wang, Shiguang Shan, Xilin Chen, “Projection Metric Learning on Grassmann Manifold with Application to Video based Face Recognition,” IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2015), pp. 140-149, Boston, MA, June 7-12, 2015. [code]
|
|
|
Discriminant Analysis on Riemannian manifold of Gaussian distributions (DARG)
To capture the underlying data distribution for robust image set classification, we represent image set as GMM and seek to discriminate Gaussian components on a specific Riemannian manifold. To encode such Riemannian geometry properly, we investigate several distances between Gaussians and further derive a series of provably positive definite probabilistic kernels. Finally, a weighted KDA is devised which treats the Gaussians as samples and their prior probabilities as sample weights.
-
Wen Wang, Ruiping Wang, Zhiwu Huang, Shiguang Shan, Xilin Chen, “Discriminant Analysis on Riemannian Manifold of Gaussian Distributions for Face Recognition with Image Sets,” IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2015), pp. 2048-2057, Boston, MA, June 7-12, 2015. [code]
-
Wen Wang, Ruiping Wang, Zhiwu Huang, Shiguang Shan, Xilin Chen, “Discriminant Analysis on Riemannian Manifold of Gaussian Distributions for Face Recognition with Image Sets,” IEEE Transactions on Image Processing, vol. 27, no. 1, pp. 151-163, Jan. 2018. [Supplemental Material]
|
|
|
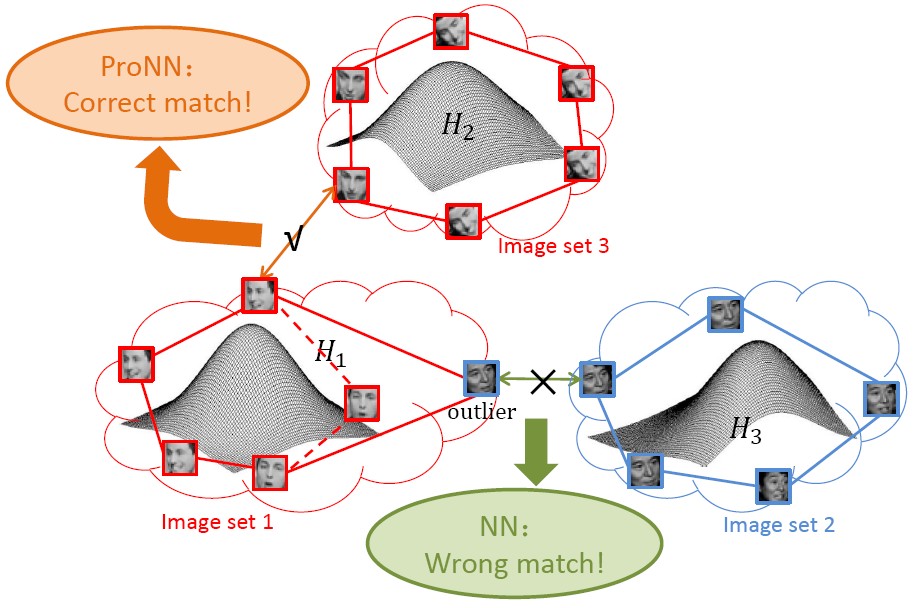
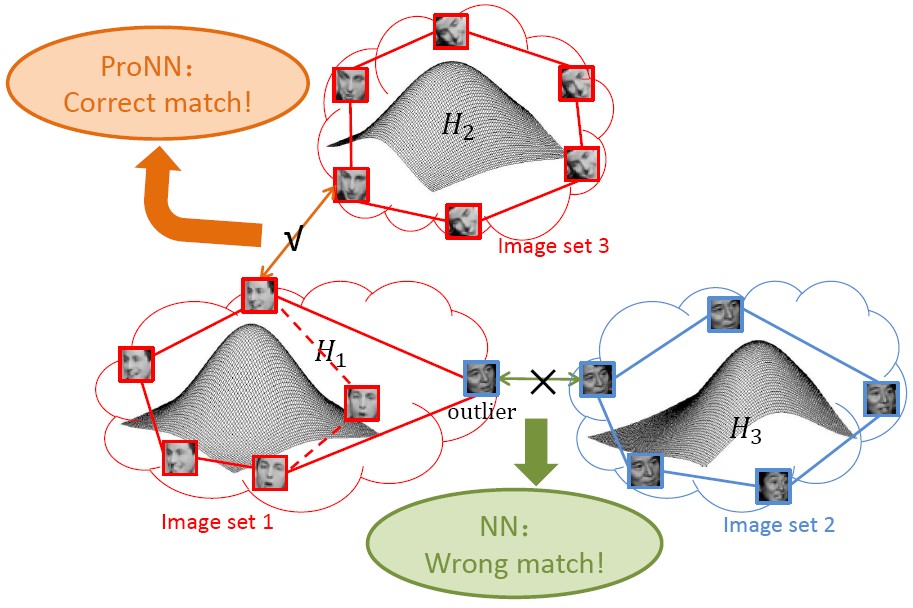
Probabilistic Nearest Neighbor Search (ProNN)
This paper proposes a ProNN method to enhance the robustness of NN search against impure image sets by leveraging the statistical distribution of image sets. We represent image set by affine hull to account for the unseen appearances and further exploit a constraint that these unseen appearances statistically follow some distribution. In search of a pair of NN points, at the same time their distance being minimized, the probability of each point belonging to the same class as its hull is maximized.
-
Wen Wang, Ruiping Wang, Shiguang Shan, Xilin Chen, “Probabilistic Nearest Neighbor Search for Robust Classification of Face Image Sets,” 11th IEEE International Conference on Automatic Face and Gesture Recognition (FG 2015), Ljubljana, Slovenia, May 4-8, 2015.
|
|
|
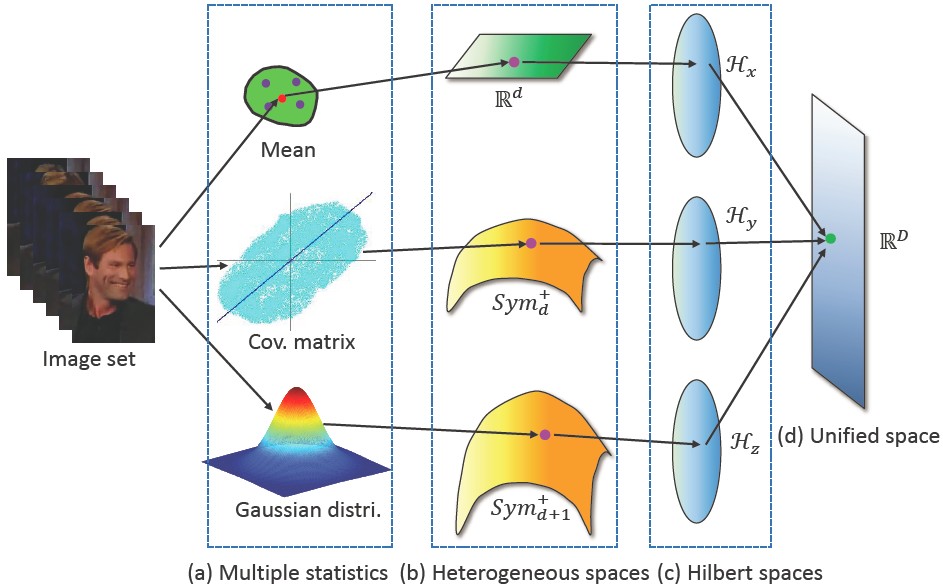
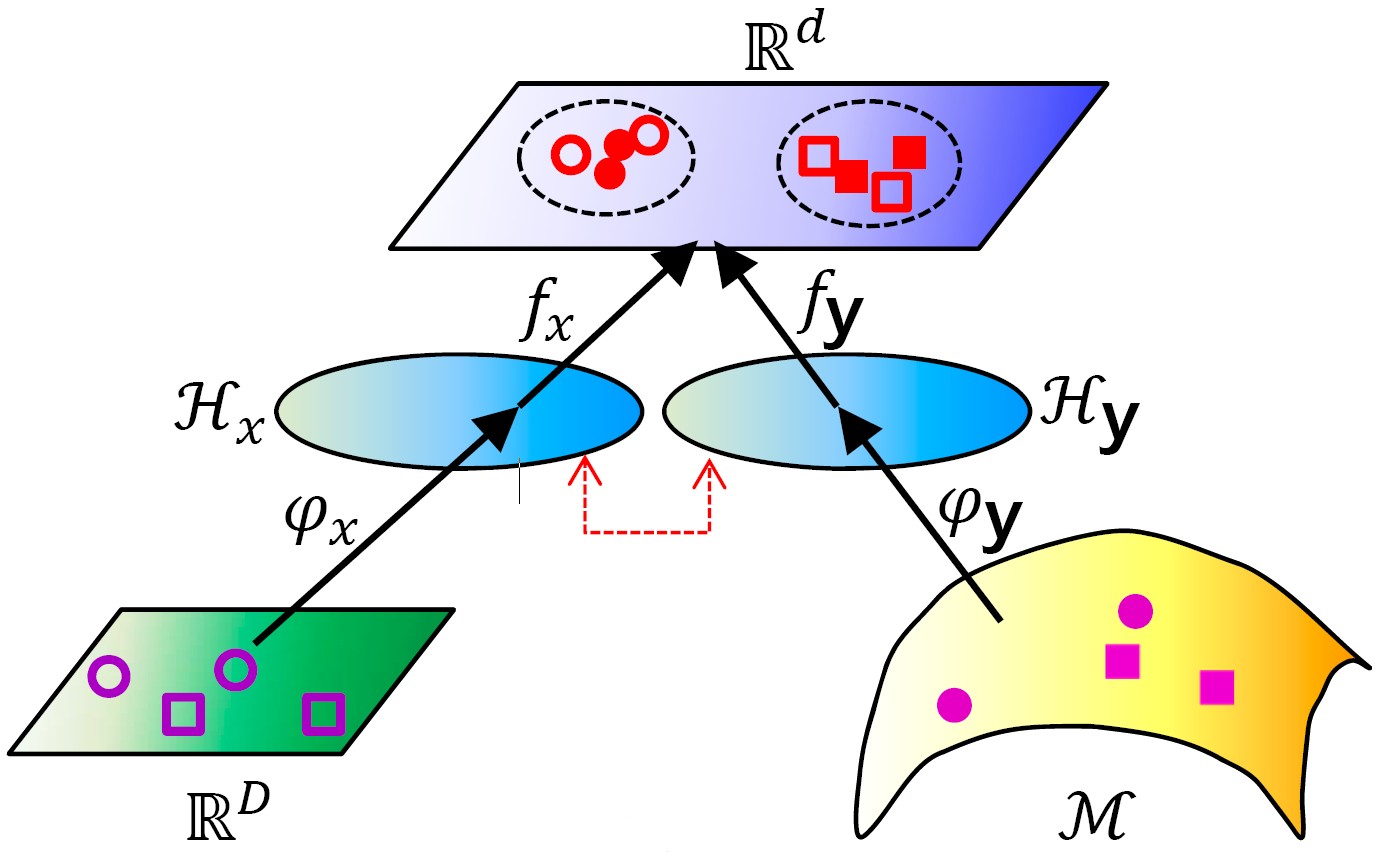
Hybrid Euclidean-and-Riemannian Metric Learning (HERML)
We propose a novel hybrid metric learning approach to combine multiple heterogenous statistics - mean, covariance matrix and Gaussian distribution - for robust image set classification. To fuse these statistics from heterogeneous spaces, we propose a Hybrid Euclidean-and-Riemannian Metric Learning (HERML) method to exploit both Euclidean and Riemannian metrics for embedding their original spaces into high dimensional Hilbert spaces and then jointly learn hybrid metrics with discriminant constraint.
-
Zhiwu Huang, Ruiping Wang, Shiguang Shan, Xilin Chen, “Hybrid Euclidean-and-Riemannian Metric Learning for Image Set Classification,” 12th Asian Conference on Computer Vision (ACCV 2014), Singapore, Nov. 1-5, 2014, Part III, LNCS 9005, pp. 562–577, 2015. [code]
-
Zhiwu Huang, Ruiping Wang, Shiguang Shan, Xilin Chen, “Face Recognition on Large-scale Video in the Wild with Hybrid Euclidean-and-Riemannian Metric Learning,” Pattern Recognition, vol. 48, no. 10, pp. 3113-3124, Oct. 2015.
|
|
|
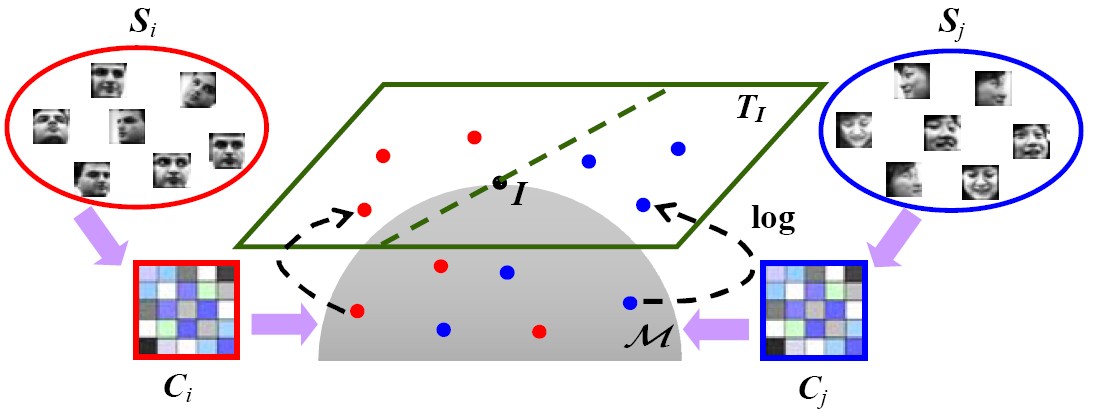
Learning Euclidean-to-Riemannian Metric (LERM)
In this paper, we focus on the problem of point-to-set classification, where single points are matched against sets of correlated points. Since the points commonly lie in Euclidean space while the sets are typically modeled as elements on Riemannian manifold, they can be treated as Euclidean points and Riemannian points respectively. To learn a metric between the heterogeneous points, we propose a novel Euclidean-to-Riemannian metric learning framework.
-
Zhiwu Huang, Ruiping Wang, Shiguang Shan, Xilin Chen, “Learning Euclidean-to-Riemannian Metric for Point-to-Set Classification,” IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2014), pp. 1677-1684, Columbus, Ohio, June 23-28, 2014. (Oral) [code]
-
Zhiwu Huang, Ruiping Wang, Shiguang Shan, Luc Van Gool, Xilin Chen, “Cross Euclidean-to-Riemannian Metric Learning with Application to Face Recognition from Video,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 40, no. 12, pp. 2827-2840, Dec. 2018.
|
|
|
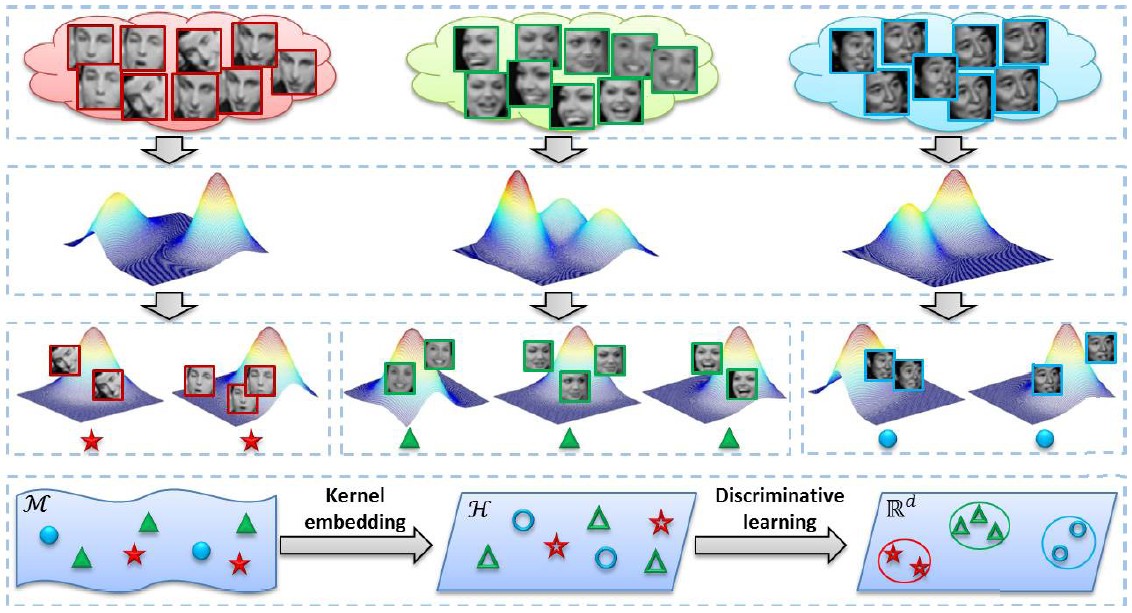
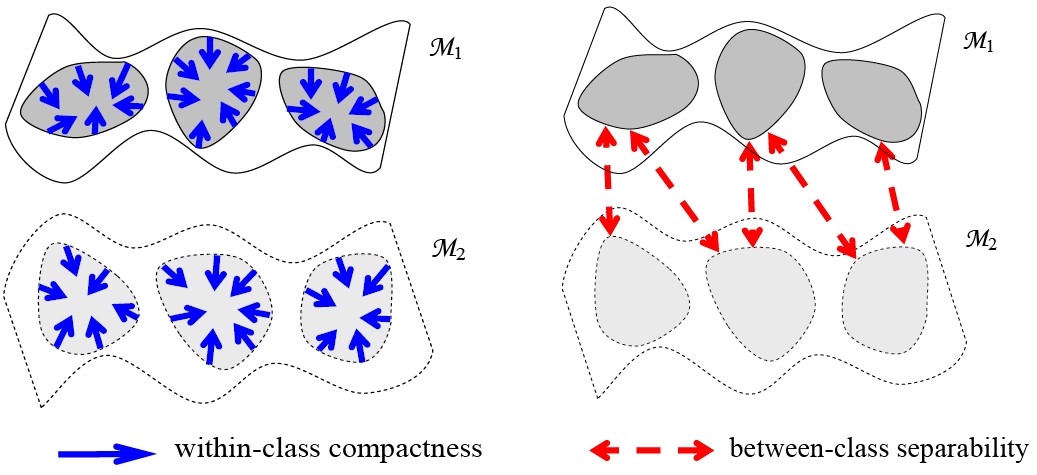
Covariance Discriminative Learning (CDL)
We model the image set with its covariance matrix and derive a kernel function that explicitly maps the covariance matrix from the SPD Riemannian manifold to a Euclidean space. With this explicit mapping, any learning method devoted to vector space can be exploited in either its linear or kernel formulation. LDA and PLS are considered in this paper for their feasibility for our specific problem.
-
Ruiping Wang, Huimin Guo, Larry S. Davis, Qionghai Dai, “Covariance Discriminative Learning: A Natural and Efficient Approach to Image Set Classification,” IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2012), pp. 2496-2503, Providence, Rhode Island, June 16-21, 2012. [code]
|
|
|
Manifold Discriminant Analysis (MDA)
We model each image set as a manifold, and formulate the problem as classification-oriented multi-manifolds learning. Aiming at maximizing "manifold margin", MDA seeks to learn an embedding space, where manifolds with different class labels are better separated, and local data compactness within each manifold is enhanced.
-
Ruiping Wang, Xilin Chen, “Manifold Discriminant Analysis,” IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2009), pp. 429-436, Miami Beach, Florida, June 20-25, 2009. [code] [Honda dataset]
|
|
|
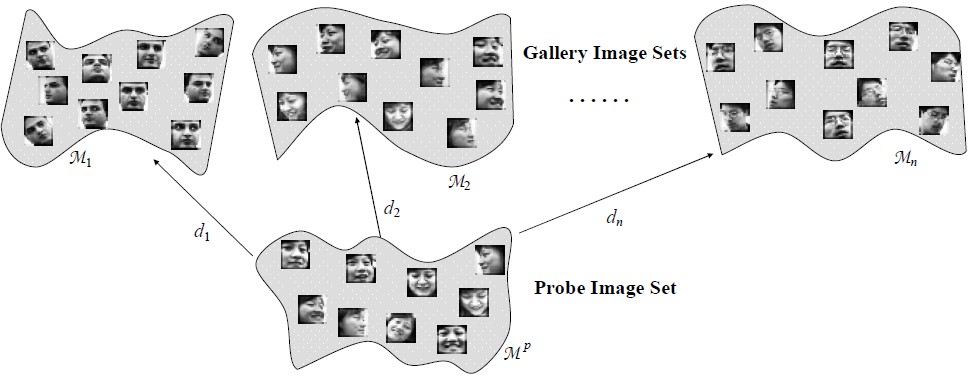
Manifold-Manifold Distance (MMD)
We propose to model each image set as a manifold, and formulate the problem as the computation of the distance between two manifolds, called manifold–manifold distance (MMD). Since an image set can come in three pattern levels, point, subspace, and manifold, we systematically study the distance among the three levels and formulate them in a general multilevel MMD framework.
-
Ruiping Wang, Shiguang Shan, Xilin Chen, Wen Gao, “Manifold-Manifold Distance with Application to Face Recognition based on Image Set,” IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2008), pp. 2940-2947, Anchorage, Alaska, June 24-26, 2008.
[webpage] [code](Best Student Poster Award Runner-up)
-
Ruiping Wang, Shiguang Shan, Xilin Chen, Qionghai Dai, Wen Gao, “Manifold-Manifold Distance and Its Application to Face Recognition with Image Sets,” IEEE Transactions on Image Processing, vol. 21, no. 10, pp. 4466-4479, Oct. 2012.
|
Dimensionality Reduction (Nov. 2005 - Dec. 2010)
Publication:

|
|
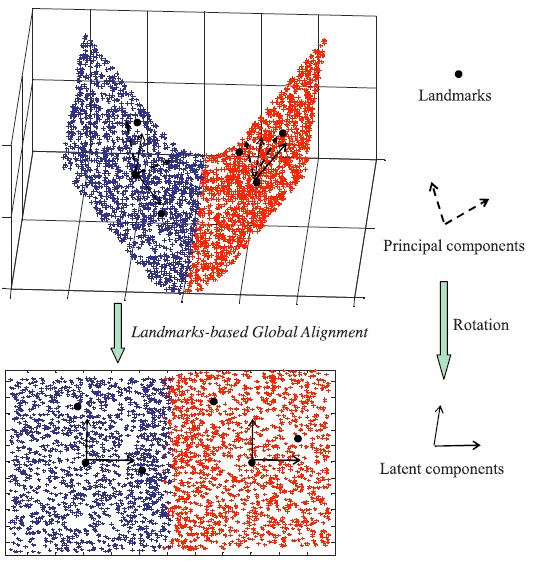
Commute Time Guided Transformation (CTG)
We present a random-walk-based feature extraction method in the graph embedding framework. The paper has two contributions: (1) It introduces the usage of a robust probability metric, i.e., the commute time (CT), to extract visual features via a manifold way. (2) It designs the CTG optimization to find linear orthogonal projections that implicitly preserves the CT of high dimensional data.
-
Yue Deng, Qionghai Dai, Ruiping Wang, Zengke Zhang, “Commute Time Guided Transformation for Feature Extraction,” Computer Vision and Image Understanding, vol. 116, no. 4, pp. 473-483, 2012.
|
|
|
Maximal Linear Embedding (MLE)
We propose a simple but effective nonlinear dimensionality reduction algorithm, named Maximal Linear Embedding (MLE). MLE learns a parametric mapping to recover a single global low-dimensional coordinate space and yields an isometric embedding for the manifold. Compared with traditional methods, our MLE yields an explicit modeling of the intrinsic variation modes of the observation data.
-
Ruiping Wang, Shiguang Shan, Xilin Chen, Jie Chen, Wen Gao, “Maximal Linear Embedding for Dimensionality Reduction,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 33, no. 9, pp. 1776-1792, Sept. 2011.
|
Face Detection (Jul. 2004 - Dec. 2005)
Publication:
|
|
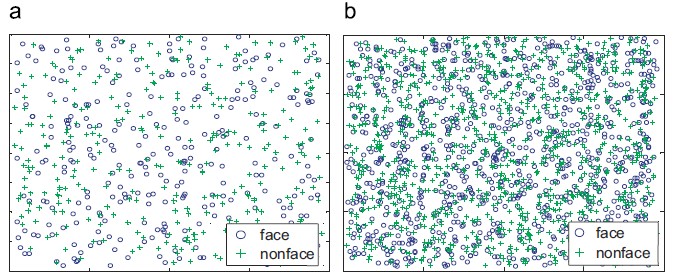
Optimizing Training Set for Face Detection
We propose a genetic algorithm (GA) and manifold-based method to resample a given training set for more robust face detection. The motivations behind lie in two folds: (1) dynamic optimization, diversity, and consistency of the training samples are cultivated by the evolutionary nature of GA and (2) the desirable non-linearity of the training set is preserved by using the manifold-based resampling.
-
Jie Chen, Xilin Chen, Jie Yang, Shiguang Shan, Ruiping Wang, Wen Gao, “Optimization of a Training Set For More Robust Face Detection,” Pattern Recognition, vol. 42, pp. 2828-2840, 2009.
-
Jie Chen, Ruiping Wang, Shengye Yan, Shiguang Shan, Xilin Chen, Wen Gao, “Enhancing Human Face Detection by Resampling Examples Through Manifolds,” IEEE Transactions on Systems, Man, and Cybernetics-Part A, vol. 37, no. 6, pp. 1017-1028, 2007.
-
Ruiping Wang, Jie Chen, Shiguang Shan, Xilin Chen, Wen Gao, “Enhancing Training Set for Face Detection,” Proceeding of International Conference on Pattern Recognition (ICPR 2006). vol. 3, pp. 477-480, Hong Kong, 2006.8.
-
Ruiping Wang, Jie Chen, Shengye Yan, Wen Gao, “Face Detection based on the Manifold,” Audio- and Video-based Biometric Person Authentication (AVBPA 2005), LNCS 3546, pp. 208-218, Springer-Verlag.
-
Jie Chen, Ruiping Wang, Shengye Yan, Shiguang Shan, Xilin Chen, Wen Gao, “How to Train a Classifier Based on the Huge Face Database,” IEEE International Workshop on Analysis and Modeling of Faces and Gestures (AMFG 2005), LNCS 3723, pp. 84-95, 2005.
|
|